Serverless in healthcare
On serverless:
Serverless computing allows users to run code without provisioning or managing any underlying system or application infrastructure, and they automatically scale to support increasing or decreasing loads. https://blogs.gartner.com/andrew-lerner/2017/07/21/serverless-is-not-networkless/
A serverless architecture forces an enterprise architectural design that modularises and isolates code. Rather than creating a full-stack enterprise application containing components for user interactions, business logic, business rules and a persistence layer, one can break-up a solution into its functional constituents isolated from one another.
A serverless function such as AWS Lambda, Google Cloud Functions or Microsoft Azure Functions can be written and deployed virtually instantly, with the hosting provider automatically scaling to manage the load. Ideally, such a function should do one or a few things very well, perhaps offering a set of application programming interfaces for clients to use with clear documentation as to how it can be called and what results might be expected. As such, the function is isolated and can be tested in lots of ways to ensure that it provides the results it is contracted to provide.
However, writing small, well-defined services that provide a limited range of function is a characteristic of any microservice. What makes a serverless approach different is that managing the deployment and scaling of that service is delegated to the hosting provider, such as Amazon, Google or Microsoft.
As a result, a rarely used operation may take up no computing resources until it is triggered by an event, such as a HTTP request. Rather than trying to implement all functionality into a single or clustered server, one can break-up that functionality into separate functions. For instance, rather than writing a service to accept uploaded image files, process them, create thumbnails and then serve them as a photo-album, one might write a range of individual separate serverless functions to handle each step of that process so that, the thumbnail generation is automatically executed after a file is uploaded.
One then imagines an overall application being simply a range of different independent pieces of functionality stitched together in a declarative manner to solve a specific range of problems.
“This declarative approach then becomes a key driver of architecture. The application speaks the language of the domain and it’s easy to detect and fix force-fits, gaps, misrepresentations and erroneous assumptions in the application each time the implementation is reviewed against the domain. A declarative interface makes it easy to adapt to changes in the domain model.” http://www.pragatisoftware.com/blog/functional-programming-and-software-architecture
“Functional programs are often organized as, sort of, a data flow graph, rather than a dependency structure. There’s declarative orchestration, right,? You just set up a whole bunch of things and you can see how they are related but you don’t have to, sort of, specify the order in which things happen, and you have referential transparency, right? I hand two values to a function, it will always give me the same value as the output because of referential transparency.” https://serverless.com/blog/bobby-calderwood-functional-programming-microservices-emit-2017/
As a result, one is forced to focus on two core perspectives: an overall perspective that takes in the combined architecture in which multiple microservices are stitched together and a granular perspective at the level of an individual microservice.
Healthcare takes steps into the cloud…
Many, if not most, health services still run applications on local servers physically sitting on their premises, running on a private intranet inaccessible to the outside world running the day-to-day organisational processes of the business and usually providing clinical information to clinicians as well.
But things are changing, many years after most industries have made extensive use of cloud-based services, we are now seeing health organisations move to host servers on commodity cloud providers, resulting in a hybrid approach in which some services run locally and others run elsewhere.
In addition, rather than buying software and installing it for local users, we are starting to see organisations starting to procure platforms-as-a-service (PAAS) in which cloud-based services are used within the enterprise. For instance, in most modern organisations, a previously private intranet is increasingly having new communication channels laid down in order to enable interaction with patients and their devices.
For instance, some providers now use PAAS-based patient portals such as Patients Know Best to enable patients to view their records. Such portals are also committing to opening up their data so that patients can choose to share their information with other providers; for instance have a look at their plans for a FHIR API). Likewise, other cloud-hosted services such as DrDoctor permit organisations to manage their outpatients by providing a platform on which patients can be contacted ahead of appointments to provide reminders and to collect outcome data.
As such, we already see health organisations making use of cloud-based services for hosting their own infrastructure and by using ready made large-scale off-the-shelf services from other providers.
As such, we already have a distributed healthcare platform; it is hosted by our organisations and unfortunately is usually disconnected so that clinical staff in one organisation cannot see health information about their patients from another organisation. Presently, we see healthcare making tentative steps to either move to or adopt cloud hosted services, but these usually remain organisationally-bound.
In parallel, healthcare is changing…
In parallel with these technological changes, we see a range of disruptive influences in healthcare highlighting three core changes enabled by new technology:
- Changes in models of care
- Patients as active participants
- ‘Hospitals without walls’
Fundamentally, advances in technology enable a transformation of care. We should look to information technology to re-imagine how citizens interact with their health services. I spoke at a recent Digital Health and Care Conference on the benefits of an open platform.
In summary, I highlighted the importance of modelling data a and workflow/process b. It has been a source of surprise and frustration that so many efforts to digitise healthcare neglect communication between professionals and with the patient, particularly when information technology has been used so effectively for communication in other domains.
This is my phase 1 vision of an appropriate enterprise architecture for NHS Wales:
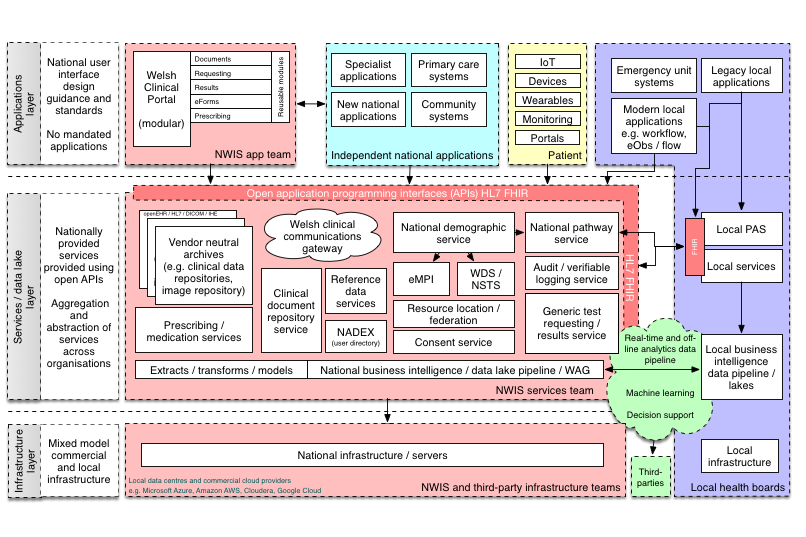
See that little box, “test requesting and results”. This is what is inside it:
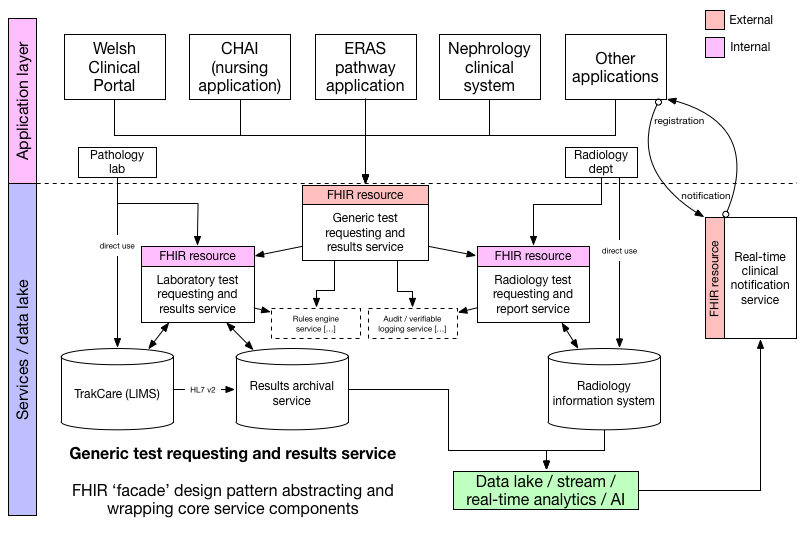
Here we abstract a new notification service that handles notifications to users such as professionals in response to a result being made available by the laboratory.
Why is this phase 1? Because I see the building blocks of our architecture becoming increasingly distributed and shared among healthcare providers. Why embed a terminology service within an application when one can pick one off the shelf and use on a subscription or pay-as-you-go model?
So what could the shift to a services-based economy mean for health?
A microservice economy means that multiple providers will offer small-scale, well-defined software functionality on a pay-as-you-go basis. We heard an announcement last week from Amazon launching their new AWS serverless application repository to enable a new marketplace of serverless apps that can be consumed by clients in order to solve real-life problems. I expect other providers to do the same, and there is ongoing work to create toolkits that permit serverless applications to be hosted by any cloud provider.
These technological trends mean that we will see large software applications and platforms being broken up into modules and as we progress, we will stitch together functionality from multiple providers to order to create clinical applications.
If we combine these trends with a need to support cross-organisational working, to make patients “active participants in their care” and create “hospitals without walls”, we can see that we are moving to a distributed, decentralised, data-driven and cloud-hosting mixed environment combining functionality from multiple providers in order to create and run our health services.
We could see core services providing data access and basic workflow models for each organisation but we will increasingly wish to federate across those services, creating a combined view of all data from multiple organisations. For example, an organisation may own or rent a document repository, probably based on IHE-XDS or FHIR document model and because other organisations also converge on standards-based open services then, subject to citizen consent, those repositories can be federated so we see a list of documents across all repositories.
Similarly, we could quickly see a marketplace of value-added functions that provide functionality layered upon those core services. For example, we might find a market for advanced natural language processing of unstructured text or services that encapsulate the application of machine learning algorithms to existing and new data. For example, why not rent a service that can, given a citizen’s distributed health record data, identify those taking a particular disease modifying treatment such as methotrexate and monitor and arrange the required three-monthly blood tests to check for signs of bone marrow suppression, renal impairment or liver damage? If that service was provided algorithmically as a microservice, given access to the required data and cost a fraction of a pence per patient, it could replace the administrators and specialist nursing staff whose job it currently is to monitor these patients.
Healthcare application sandboxes
It is easy to see how some serverless resources might work. They may simply provide a HL7 FHIR resource endpoint and allow applications to use its application programming interface as if it were hosted locally. Imagine a distributed audit trail functionality, made available via the HL7 FHIR AuditEvent endpoint. FHIR servers can support one or many different types of resource and it is not difficult to imagine a single serverless application providing a capability statement documenting only a single end-point and providing that functionality in an automatically scalable fashion.
Such a model would be fine for a single organisation, but how can that work in a distributed fashion?
But we need to create a distributed platform that means that we can plug-and-play these different microservices and make them useful to the wider health economy. To do that, we must design a sandbox environment in which user facing applications running on desktops, web-pages and mobile devices and backend serverless applications can be dropped and expect to work.
Much like Apple has “app stores” for mobile and desktop applications and Google has similar for Android, we need to consider what architecture is required for user-facing and serverless applications to be deployed easily and quickly into our distributed healthcare economy. Amazon has introduced the AWS Serverless Application Model which annotates a serverless application with information about its dependent resource types needed for its proper operation.
So how could this work for our methotrexate monitoring example serverless application? It needs to be provided with a sane runtime environment from which it can safely access the information it needs and to take any actions that are necessary. So what does it need access to?
- a test results service to get results including renal profile, full blood count and liver function tests
- a test requesting service
- a document or clinical narrative repository
- a audit event logging service
In software engineering, we frequently use a concept called dependency injection to pass through dependencies to a subsystem so that we can configure it appropriately and appropriately isolate separate functionality. As such, much like the AWS Serverless application model referenced above, we need to consider how we glue together sensitive health data with different services, perhaps provided by multiple different vendors?
Given that all the functionality our serverless application needs is provided by HL7 FHIR resource endpoints (diagnostic reports, procedure request, documents and audit), it might be possible to simply pass in those endpoints as dependencies either when the service is provisioned or even when it is called.
And now the logical question becomes, how do we manage looking up and accessing resources across a distributed health enterprise, particularly when we are dealing with sensitive private data?
As I wrote in the part three of my disruptive influences series:
Applications running on Apple’s iOS provide a useful analogy. In order to gain access to components of the underlying device and its operating system, such as the camera, the photo archive, location services etc, the application must use the appropriate API which forces explicit user consent. This “sandbox” environment means that an application is prevented from accessing resources to which consent has not been provided and presumably can log each and every attempt should that be required.
Can we do the same for health applications and services? It seems to me that we can create tremendous value from healthcare data - for patients, for health professionals and for society - but the foundation must be to allow that information to be organised in such a way that we can make it “universally accessible and useful” subject to individual consent.
The answer to our distributed future, built declaratively to glue together distributed data and services, is underpinned by a robust model of citizen consent that itself is hardwired into the systems to manage resource lookup and access. We now need to start thinking about how this will work, and how a “healthcare application model” might operate so that we can make use of new technology to improve the care of our patients. We need to start talking about how an “API gateway” might work for healthcare.
Thank you.
Mark
Footnotes
a: Data modelling ensures that we create semantically interoperable data coded in such a way as to make it meaningful to multiple disparate units of software. Such data may represent all types of clinical information, such as a blood pressure measured with a traditional sphygmomanometer on the right arm or the result of a laboratory test. As such, a focus on data standards is important so that there is agreement as to how individual items are coded and contextual information can be understood, such as who performed the measurement, how it was done and when.
b: While a prospective clinical record of structured and unstructured information forms our medical record, the medical record does much more than simply record a narrative of events. Our medical records are our clinical practice, enabling processes and workflow. Paper medical records have important properties in enabling workflow; their presence on my desk with a post-it note tells to do something vital. It is therefore important to conceptualise not only a model of healthcare data but also model the workflow, processes and communications that enable care.