Pseudonymous consent
Update: 8th April 2017. I have refined the data model in a subsequent post.
In earlier posts relating to “What I would do if I were Google” and “Balancing information governance and innovation in the NHS”, I discussed the importance of balance between information governance and open innovation within healthcare informatics focusing on the difficulty in handling sensitive medical data.
Writing a blog forces one to reflect; for instance, what is it that you are trying to do? I’ve concluded that my primary objective within healthcare informatics is to:
- make healthcare information available at the point-of-care in order to support clinical carea
To achieve that, I want:
- better use of real-time analytics to aggregate data among patient cohorts and support clinical decision making
- a mixed-economy of healthcare applications that can interoperate and leverage core infrastructure and services with a reduced focus on monolithic enterprise-wide systems
And to achieve those, I want:
- greater use of structured clinical information captured and used at the point-of-care including use of robust information models, open standards and terminology such as HL7 FHIR, openEHR and SNOMED CT.
- an open-source infrastructure to permit interoperability between vendors.
- a robust information governance framework
Supporting information governance
One can support information governance by adopting appropriate policies and procedures, by creating formal legislation, toolkits and by instituting technical solutions such as authentication, authorisation, secure audit logs and encryption.
Essentially we need to strike a balance between making clinical information available and ensuring that this sensitive information is not seen by the wrong people in a complex, heterogeneous and distributed environment in which there are multiple actors such as clinical staff, patients, managers, organisations and commissioners.
I think that there are three broad concepts we need to cover:
-
Pseudonymisation and data linkage.
-
Secure and verifiable audit trails
-
Put patients at the heart of what we do and give them control.
I have previously discussed the use of pseudonymisation as a technique to permit safe data linkage within and between disparate datasets. In addition, I covered the use of a project- or service- specific pseudonym that could uniquely identify a patient for that particular research project or clinical service. Importantly, pseudonymisation uses a one-way mathematical function so that, given a pseudonym alone, we cannot re-identify a patient. However, we can re-link these data if we have the shared secrets that were used to generate the pseudonym.
I gave an overview of Merkle trees in a previous blog post. Essentially, although I have built in audit trail functionality into my own EPR, there is nothing stopping me accessing patient records inappropriately and removing those log entries directly from the database as I have administrator access. Do you trust me? Perhaps. But do you trust a commercial entity? Perhaps not. A verifiable audit log potentially solves this issue, by ensuring that no-one can tamper with the log.
Putting patients in control of where and how their information is used means that there are no surprises because patients have explicitly agreed.
Key security concerns
Is it possible to create an architecture which is secure-by-design?
The use of pseudonyms generated on a per-use or per-service basis, possibly on the fly, potentially allows an interesting security feature in that inappropriate dataset access cannot occur simply because the data cannot be linked to the patient, rather than relying on systems themselves try to manage which data sources are permitted or not. Access to data is therefore the result of data linkage.
As a result, it becomes possible to allow untrusted third parties access to an infrastructure but their access to disparate distributed data sources is impossible as a result of a lack of linkage. In addition, by virtue of requesting access, the third party must make a data access request and therefore have their access logged appropriately.
One fundamental security concern is that a centralised registry of permissions, opt-ins and opt-outs in itself gives away important potentially patient identifiable information. For instance, membership of a cohort of patients in a genito-urinary clinic in itself gives information to potential third parties. Therefore, it is important that such information is inaccessible by design.
Sensitive information will be both stored and subsequently transmitted; both require protecting. The most difficult is protecting stored data and I have tried to create a proof-of-concept that could cope with whole system compromise. Assuming an attacker has full access to a dump of the database, it should be possible to take reasonable precautions to prevent re-identification. However, this requirement means that simple join-tables in a relationship database between a patient and their consent/permissions cannot be used.
Proof-of-concept
There is nothing like trying to create a small working solution as a proof-of-concept.
The source code is available here: https://www.github.com/wardle/openconsent. Conceptually, the data model is as follows:
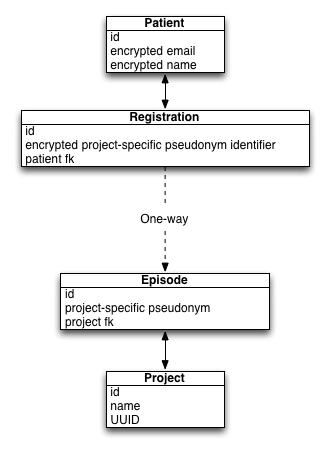
- Here the Patient entity records the name of the patient and uses an email address for login. When a user creates an account, the password is used to create a salted digest for future password-checks and used to create a different digest used to encrypt an encryption key. This key is used to encrypt other information including the name of the patient and the episode identifiers held in the registrations table.
- The registration table simply stores encrypted pseudonymous identifiers. There is a one-to-many relationship from patient to registrations.
- A project represents a clinical service or research project. Future versions will include additional information such as a URL to an organisation or service homepage as well as service authentication credentials.
- An episode stores a project-specific pseudonymous identifier and will store the patient’s explicit choices regarding the use of their data in that context. It will be here that a verifiable audit log is required to track changes in choice so that we can vouch that nothing has tampered with the transactions that have occurred at the episode level.
This data model is working and is unit tested. An example of creating a patient and understand that they are part of a specific project is shown here, if you can understand java code. Essentially a patient is registered to a project and I show that we can find that registration subsequently.
The encryption key is generated randomly. It is encrypted using a key derived from a digest of the patient’s password. The encryption key can only be decrypted with access to the patient’s password but this is never stored. The digest used to validate a patient’s password is stored but is calculated differently to the digest used as the key for the encryption key. The encryption key is used for encryption and decryption of sensitive information relating to that patient. By decrypting the registration information, the application can get a list of episode identifiers for that patient.
I do need to add an encrypted global pseudonym that is not exposed to research projects and clinical services to allow data linkage once a patient’s account has been validated. More details of this are given below.
The next steps will be to expose this functionality as a REST service. My plan for the eventual architecture is shown here with the unimplemented pieces in grey and the already implemented model in blue.
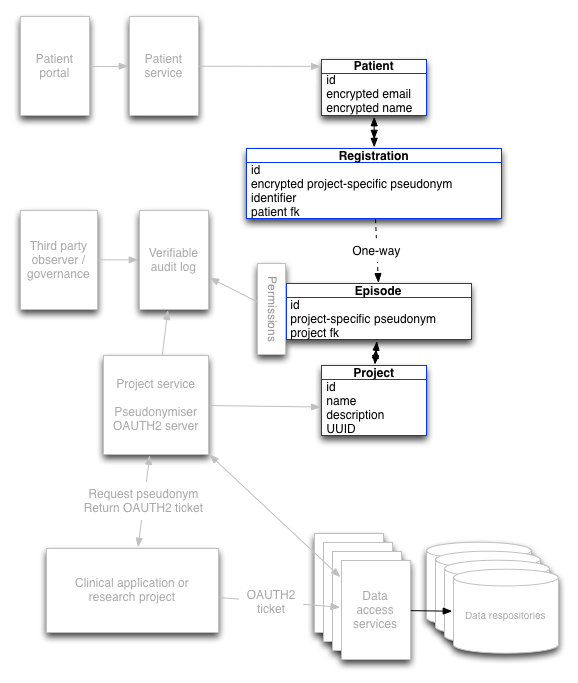
The following sections describe how the system works to track consent in a safe way.
A research project
- A research project is registered with a project-specific consent form.b
- A research project creates an episode using the patient’s details and so needs to know their details to pass in to generate a pseudonym.
- If that project subsequently wants to know whether a patient they are seeing has consented, they can pass the patient’s identifier (e.g. NHS number) and date of birth and get any active episodes.
- However, because openconsent understands that such a service is opt-in, it will only issue authorisation tokens if the episode has been validated by the patient explicitly.
- If a patient has consented, then the project can submit the pseudonym to receive an OAUTH2 token. OAUTH2 is a distributed authorisation framework which allows application to obtain limited access to a data repository. A verifiable audit log records the transaction using the pseudonym.
- Should a patient’s consent be withdrawn, or not exist in the first place, then no data is returned. No further work is possible.
Validation of permission by the patient could occur in a variety of ways:
- when a member of the research team meets the patient and shows them a QR code that is readable by a mobile device application.
- a QR code that links to a web application portal for the patient
- manually typing in the project-specific pseudonym
Once linked, a patient account stores the registration information in an encrypted format and can then find the episode information and alter their permissions within the episode.
The data store would provide data linked only via the pseudonym preventing simple re-identification of patients.
A clinical service
A registered clinical service would expect to always have authorisation to patient data, but audit trails of information requested would still be recorded as above. Clinical users would authenticate with their clinical applications and those applications would themselves authenticate and become authorised to access clinical data, obtaining an OAUTH2 token to access the appropriate data.
A clinical service would therefore create an episode using the patient’s information and no explicit consent is required for openconsent to issue authorisation tokens. However, there is a problem here. How can a patient remove their consent for this specific use of their data? There is no way an episode can identify the patient or indeed a registration entity corresponding to that episode as a result of the one-way link between a registration and an episode.
I think that there are two options:
-
Iterate through all registered projects and calculate on-the-fly a pseudonym for each and look for matches within the episodes. This would work only if we store the information required to generate the pseudonym in the Patient entity. This is possible but may struggle to scale if there are many projects.
-
Add a global but private pseudonym that, once recorded acts to validate that the patient account is owned by the person we think. However, this private global pseudonym cannot be shared with individual services and is built from a recipe of immutable information about the patient using a different salt. Once the information used to built the pseudonym are validated, the global pseudonym can be recorded encrypted in the patient’s own account. This can then be used to link project-specific pseudonyms to a single record.
I consider option (2) to be preferable but will work to prove that in the proof-of-concept project.
For option (2), the global pseudonym will also need to be stored, privately for an episode. Thus, for a validated patient account, the service can then find all episodes relating to them even though there is no corresponding registration. If a patient is not happy with the use of their data for that purpose, they can mark it as such. In the model, a registration is built to link the patient with the episode, and their new preferences are recorded in that episode with the change recorded in the verifiable log. From that point, service access will not be permitted.
For opt-out services, most episodes will not be linked to from a registration entity except if a patient has explicitly opted-out. If the patient has done so, then the episode will have had the permissions changed.
The patient
A patient should be able to login via their portal. From there, they can see their registered projects and services by decrypting a list of project-specific pseudonyms. In these, they can opt-in of research and opt-out for non-research clinical uses on a case-by-case basis.
For research, a patient may engage with the research team or a project-specific application or generic sign-up application and link their account to the project. Essentially, in the data model, I create a registration entity that maps to the episode entity for that project and patient. A patient may then easily remove their consent at some point in the future, with any changes made to the episode and the transaction logged with the verifiable log.
For clinical services, a patient would need to register to opt-out as discussed above.
Problems and requirements
- The software is a simple proof-of-concept at the moment and is incomplete. I need to:
- integrate an OAUTH2 server. Can Apache Oltu do this?
- add REST endpoints. This is quite easy using LinkRest and standard JAX-RS.
- link to a verifiable log. Needs evaluation. Plan for simple log that can replaced with proper verifiable version in future. I’d plan for the verifiable log to be on a remote service. Could I use Trillian?
- build user interface components to expose the tools to the patient (although this would be a long-term aim).
- build data repository wrappers to check for OAUTH2 tokens for permission to access.
Further questions:
- Is AES encryption good enough for encrypting the data fields within the patient record and the associated registrations? At the moment, this uses 128-bit keys, but it would be straightforward to increase the key length in production.
- Can this be a distributed system? Probably. The software supporting the Patient - Registration can run on a separate service than the Episode - Project components, and there could be multiple latter services, essentially creating a registry of data registries?
Essentially, the design principles here are:
- decoupling applications from data stores
- put patients in charge of opt-in and opt-out for access to their data for different purposes
- create a secure architecture using encryption and pseudonymous linkage, so we can offer guarantees about data governance while permitting large-scale access by third parties.
This is a project in development so thoughts and suggestions are most welcome!
Mark
Footnotes
a: I originally wrote “to support the care of patients”, but that implies that it is care that is done to patients rather than a partnership; the words we use to frame a problem potentially limit our ability to solve the real issue.
b: In the PatientCare EPR, I have an electronic consent system with specific items of consent mapped in an information model exposed via a REST service. An iPad application can use this to build a ResearchKit based consent form automatically and dynamically. The following video demonstrates this functionality in which I edit a consent form electronically and the change is seen in the ResearchKit based application, here running on an iPad.