Building a 'neuro-rehabilitation database'
I built an electronic patient record and it’s been quite successful. It’s taught me a great deal about how to recognise how to modularise and decouple different data and software components. It’s been running since 2009 and is in live use.
It’s a large project, and I can’t conceive of everything in one go, so even though I’m the only developer, adopting an architecture that enables modularity, adaptability and flexibility is important.
One important aspect of my work is being able to compose individual building blocks together to solve problems, and to do that in a declarative, rules-based way. This means I can build solutions have them deployed and working in live clinical environments in less than a day.
Most users think that the software is designed for them, and in a way it is. People refer to it as the “MS database” or the “referrals database” or the “Parkinson’s database” or the “MND database” but each is simply a prism through which to view a single digital patient record.
To illustrate the point, it’s quite easy to see the common foundational services:
- Patient identity - lookup arbitrary identifiers such as any Welsh hospital identifier or NHS number or search (Google-like) by name
- Staff identity and authentication - including lookup and email via the NHS Wales active directory service
- Finely-grained access control by the runtime registration of both patients and users to clinical services, teams and research projects
- Tracking episodes of care and configurable encounters and data-collection forms.
- Clinical terminology, value set management and organisational data services
- Document creation and publication services, to create documents from data and publish those in local and national document management services such as Cardiff clinical portal and Welsh Clinical Portal.
With these building blocks, let’s build a neuro-rehabilitation database. I’m going to live blog this work.
Neuro-rehabilitation
When I designed the system, I recognised I’d need to make it easy to change the things that would change. Registering a new logical service or research project had to be easy and involve no software code. In fact, I wanted to ensure that I could configure lots of things at runtime, and I made SNOMED CT the lingua franca. If I need to write code, I wanted to make it as modular as possible and ensure that first changes didn’t affect what was already working and second, that I didn’t have to make changes anywhere else.
The neuro-rehabilitation team wanted to track a cohort of patients and make assessments about their rehabilitation need.
So I can create a new service using my administration portal:
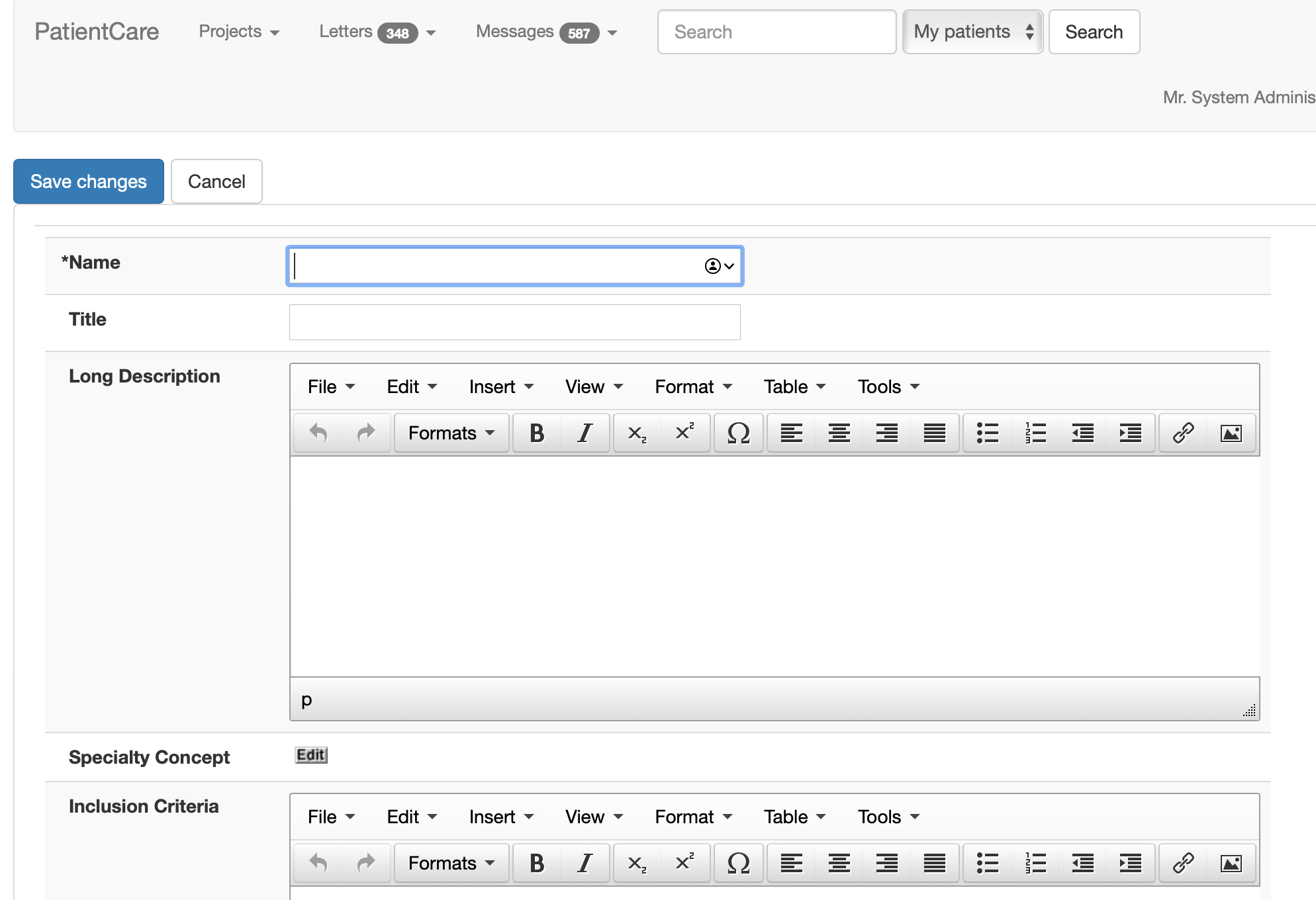
I can configure a project either as a clinical service or a research project. These have different semantics but all are organised in a hierarchical fashion so that properties are inherited from parent projects, and that users and patients are linked to services and projects via registration or episodes of care, and that means when you as a user search for John Smith, you’ll only get patients known to one of your registered services.
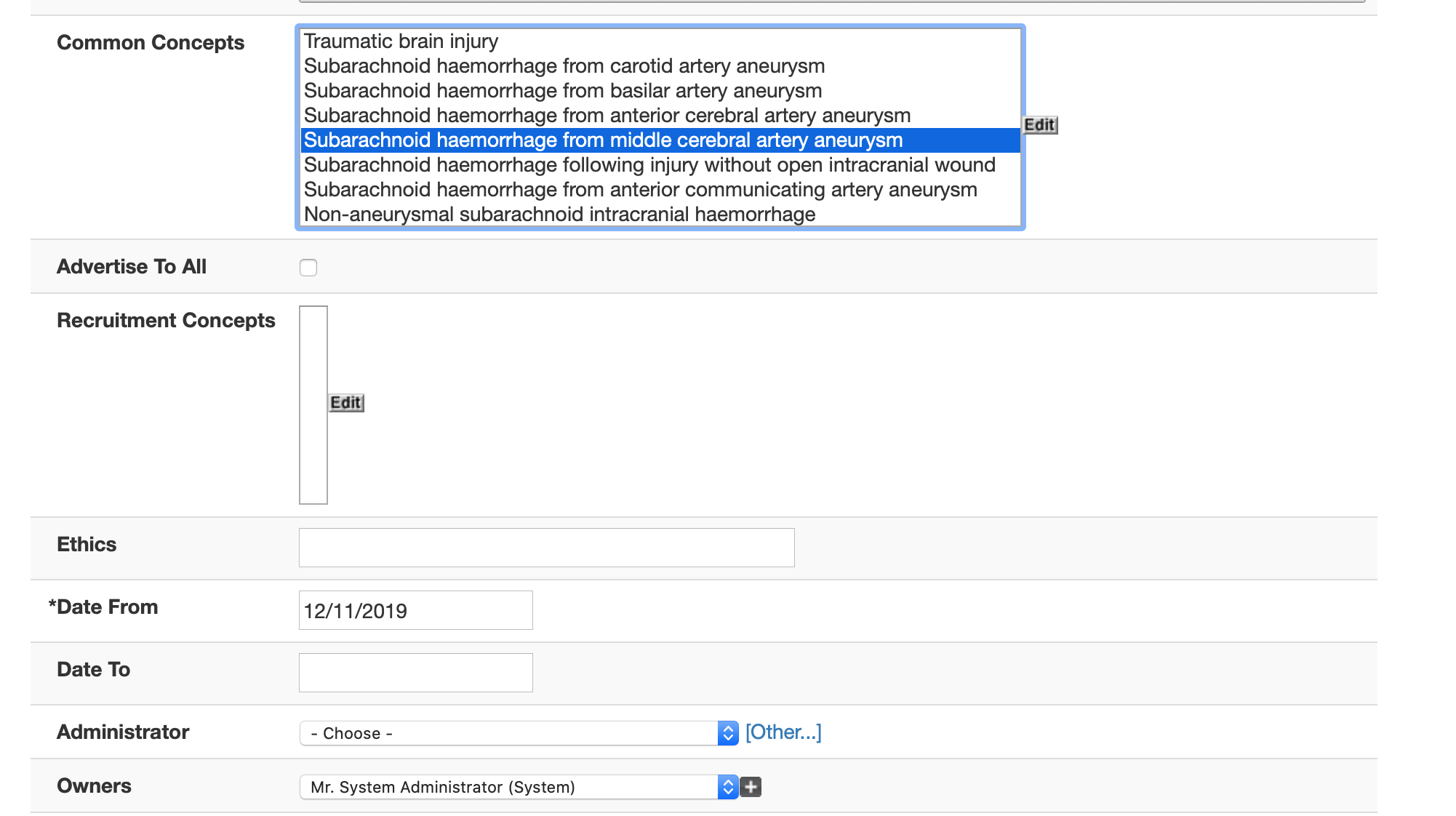
For a service or project, I can configure common SNOMED concepts so that drop-downs and picklists and autocompletion boxes get configured based on who you are and who you are seeing. This means users feel as if the system is designed for them, even if really it’s just simple configuration. I configure the specialty using SNOMED-CT.
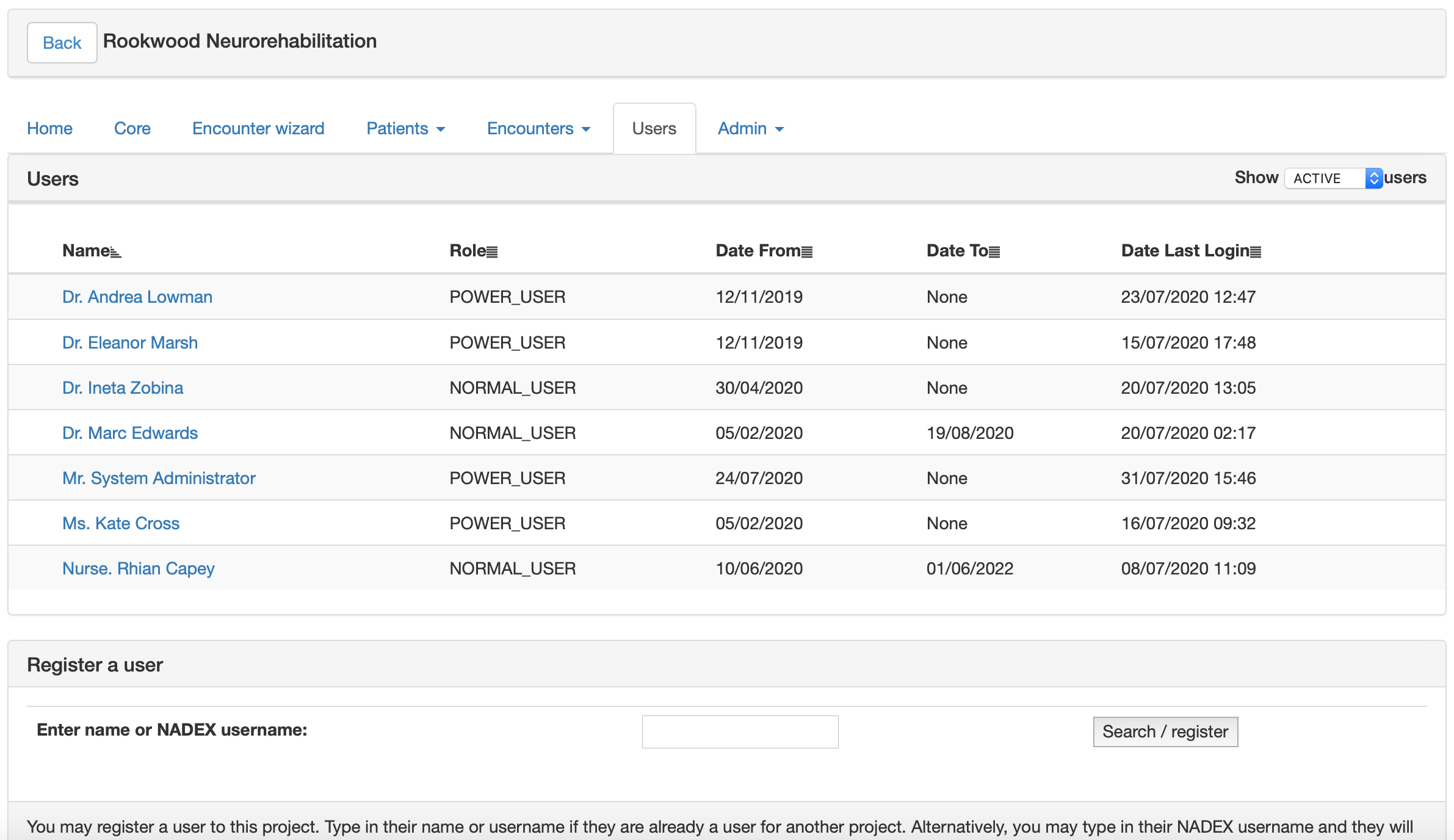
I wanted users to be able to manage their own services, so all projects have per-project security permissions. This means I don’t need to be involved in registering users, and all “power users” need to do is type in a username and the software fetches their details from the national directory.
Each service can have different types of encounter. This is usually dependent on the service or project at hand, so is very customisable. Here I’ve simply created three for now, ‘correspondence’, ‘inpatient review’, and ‘telephone call’.
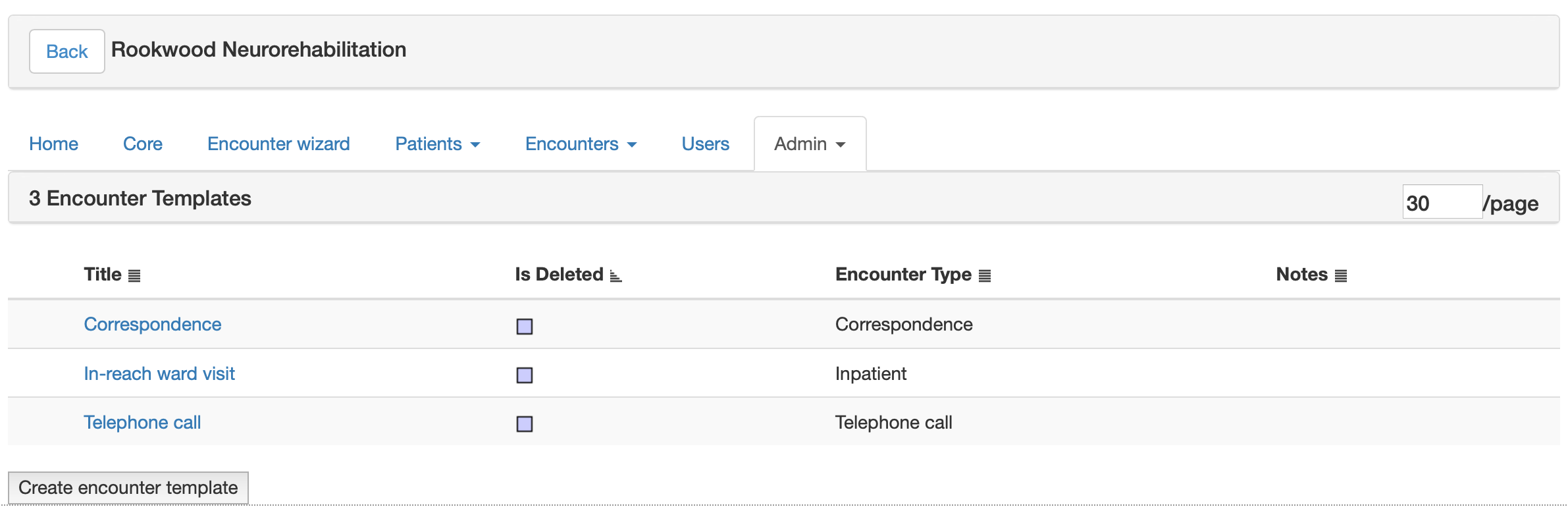
And for each, I configure some common forms. Users can manually record others, but this streamlines the process for them. Each encounter can be associated with fetching lists from external systems such as PAS making it useful for clinics.
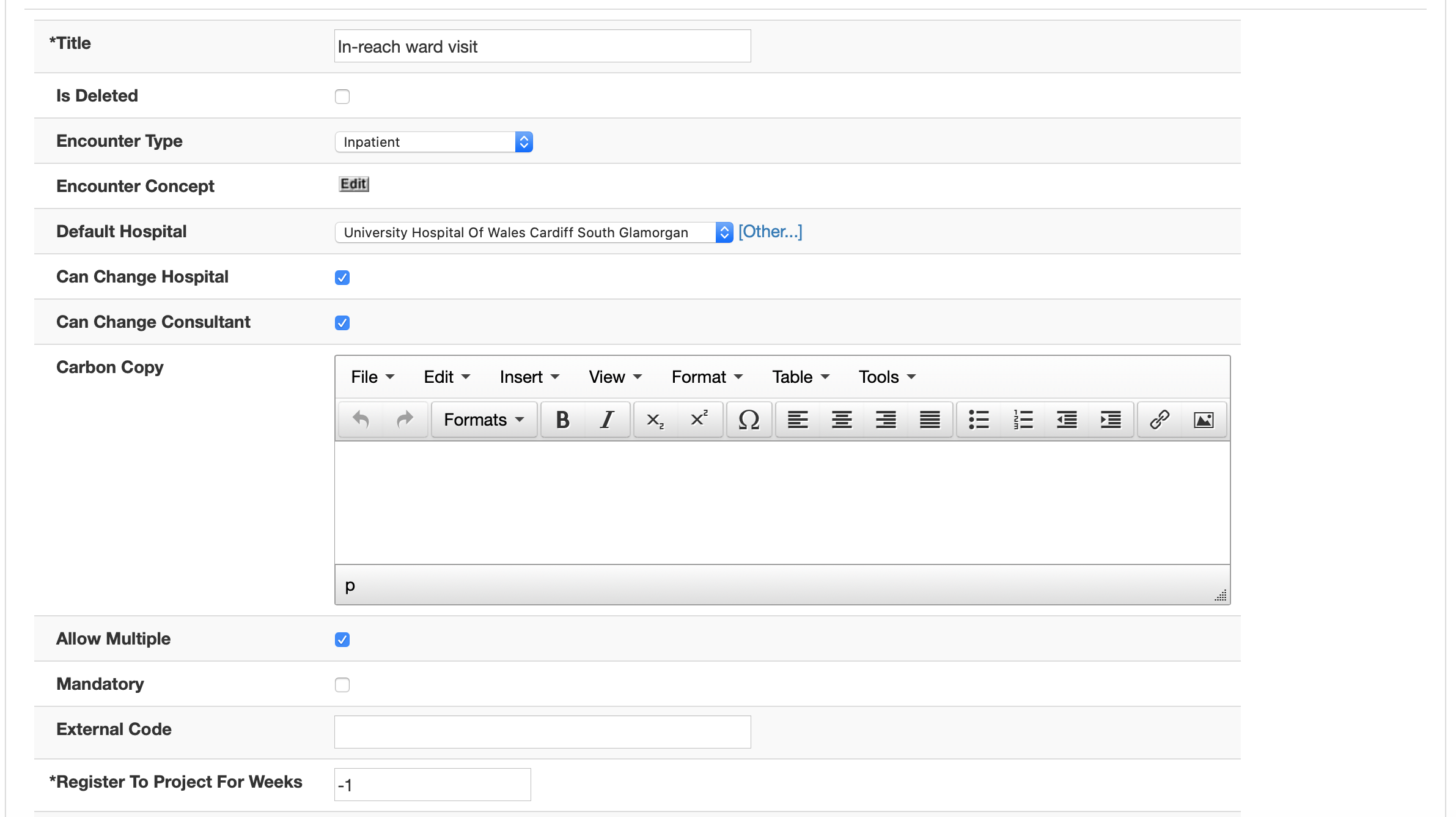
Here I add a medication review (this used dm+d to record medications and changes to medications), a procedure form (useful for recording stuff done), a botulinum toxin form (a specialised procedure form), a MOCA (a cognitive test), and a rehabilitation assessment form.
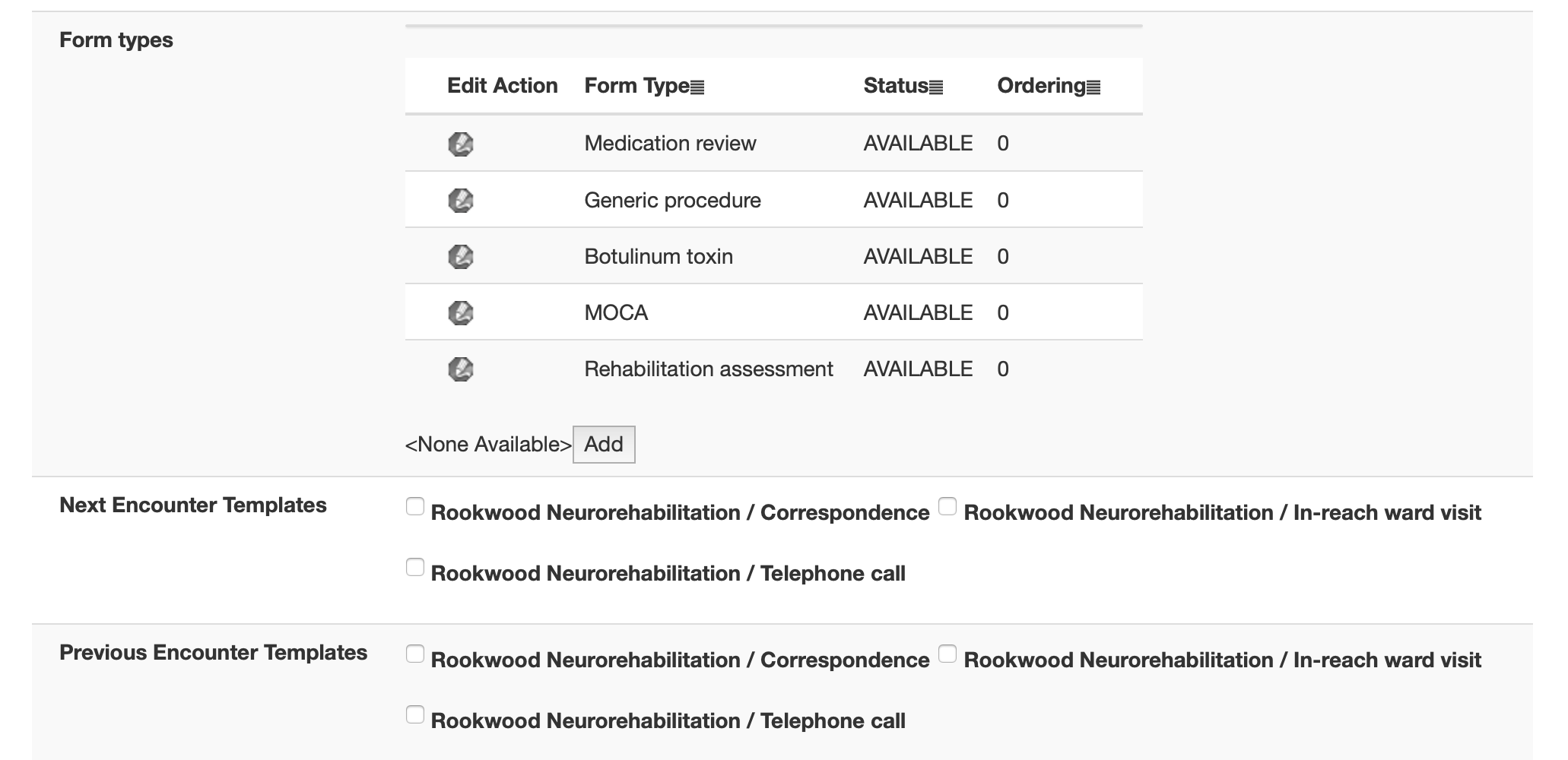
Data collection forms are linked to encounters, which are linked to episodes, which are linked to patients. Each episode is linked to a project or service, and each project or service has a list of registered users. It’s quite straightforward to see how I implement finely-grained information governance using this model. Each user thinks the system is designed for them.
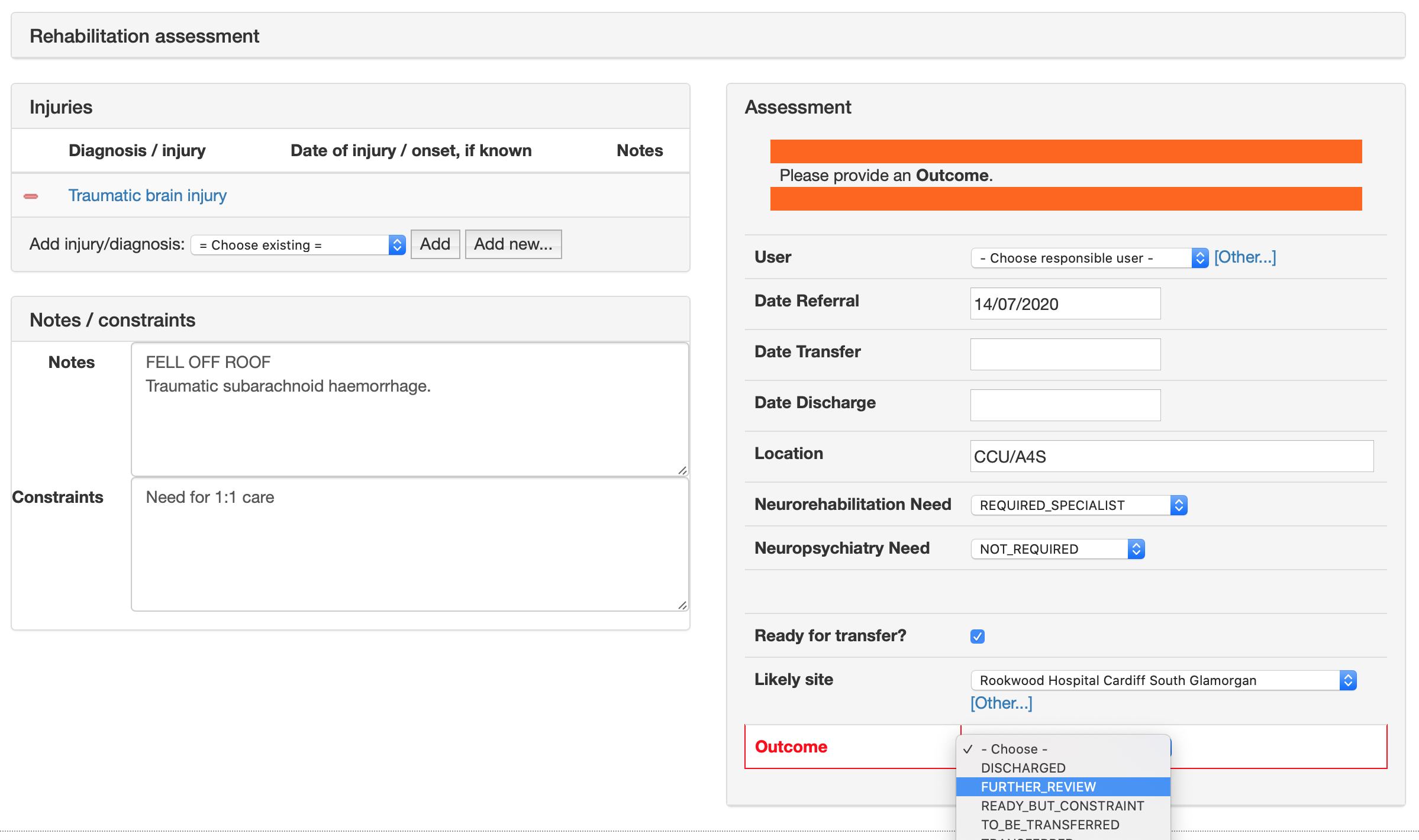
Here’s the rehabilitation assessment form. Its contents are automatically populated from information already in the electronic record, but users can make changes and then save. Diagnoses are recorded using SNOMED CT so later we can stratify our patient group by category of injury for example.
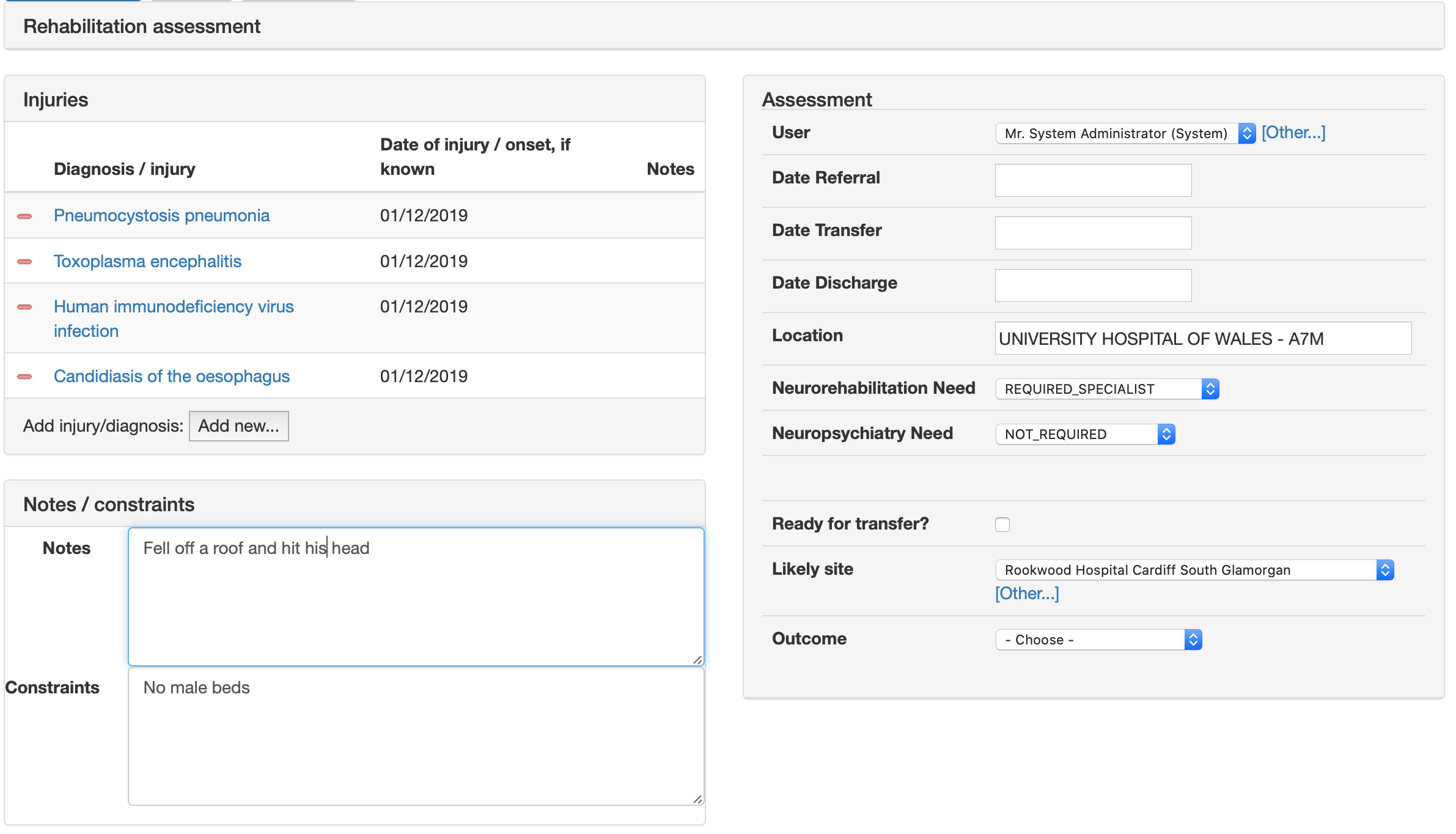
We can add arbitrary validation so that we help users enter the right information:
We already have a “botulinum toxin database”, so I can simply re-use that form for this service. Some rehabilitation patients need injections of botulinum for spasticity or jaw problems.
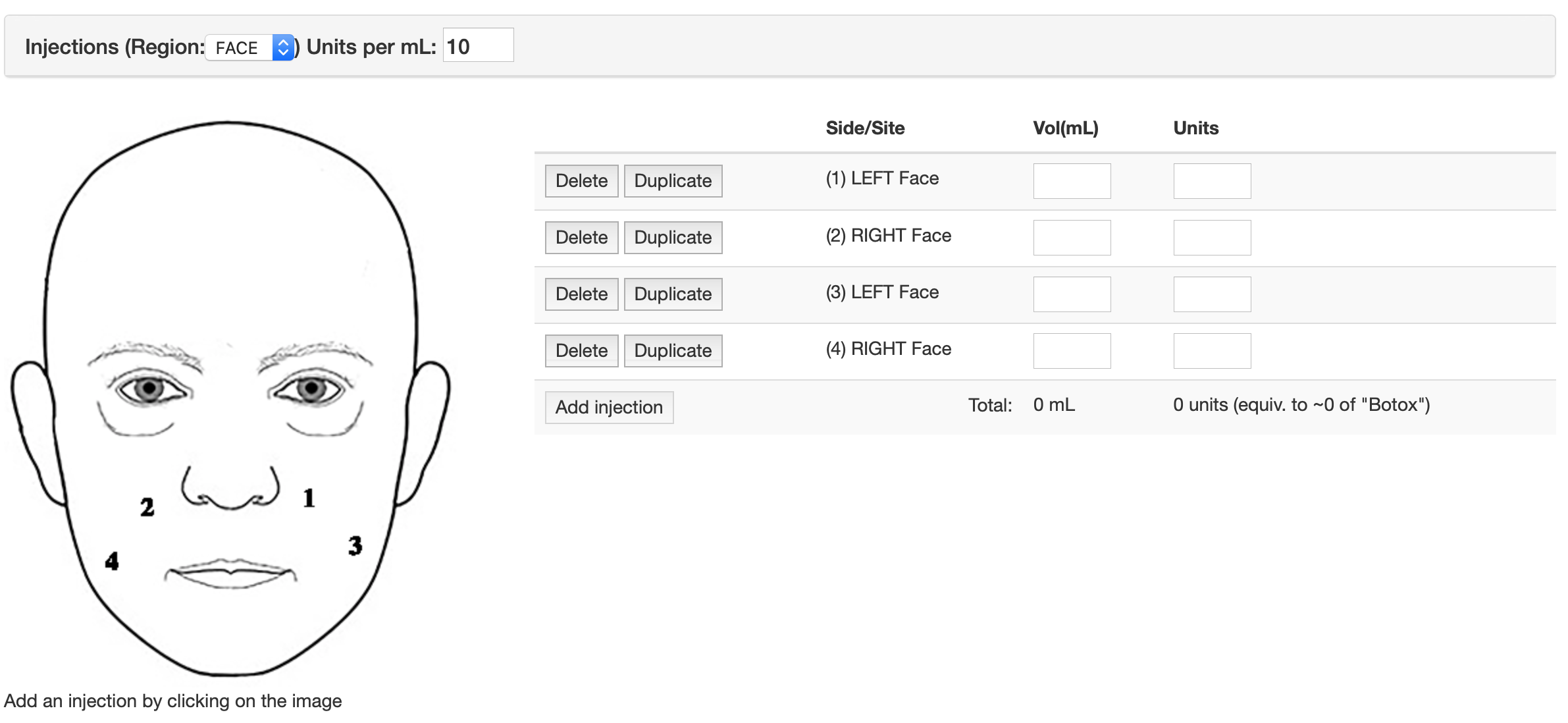
All these data are coded using SNOMED CT, even when you’re simply clicking on a diagram.
I have lots of pre-built forms and it can take between 5 minutes and an hour or so to build a new one, depending on complexity. So other modules don’t have to understand the data within each form, forms generate SNOMED CT artefacts that can be used to dynamically configure the user interface depending on need.
Each project or service can send clinical documents to other document repositories. I configure a “report” using a PDF template that will watermark the generated document. The document is generated from data. It’s a shame but none of the receiving document repositories can yet understand the structured information encoded with these documents, but accept only a PDF and a small amount of non-standard metadata.
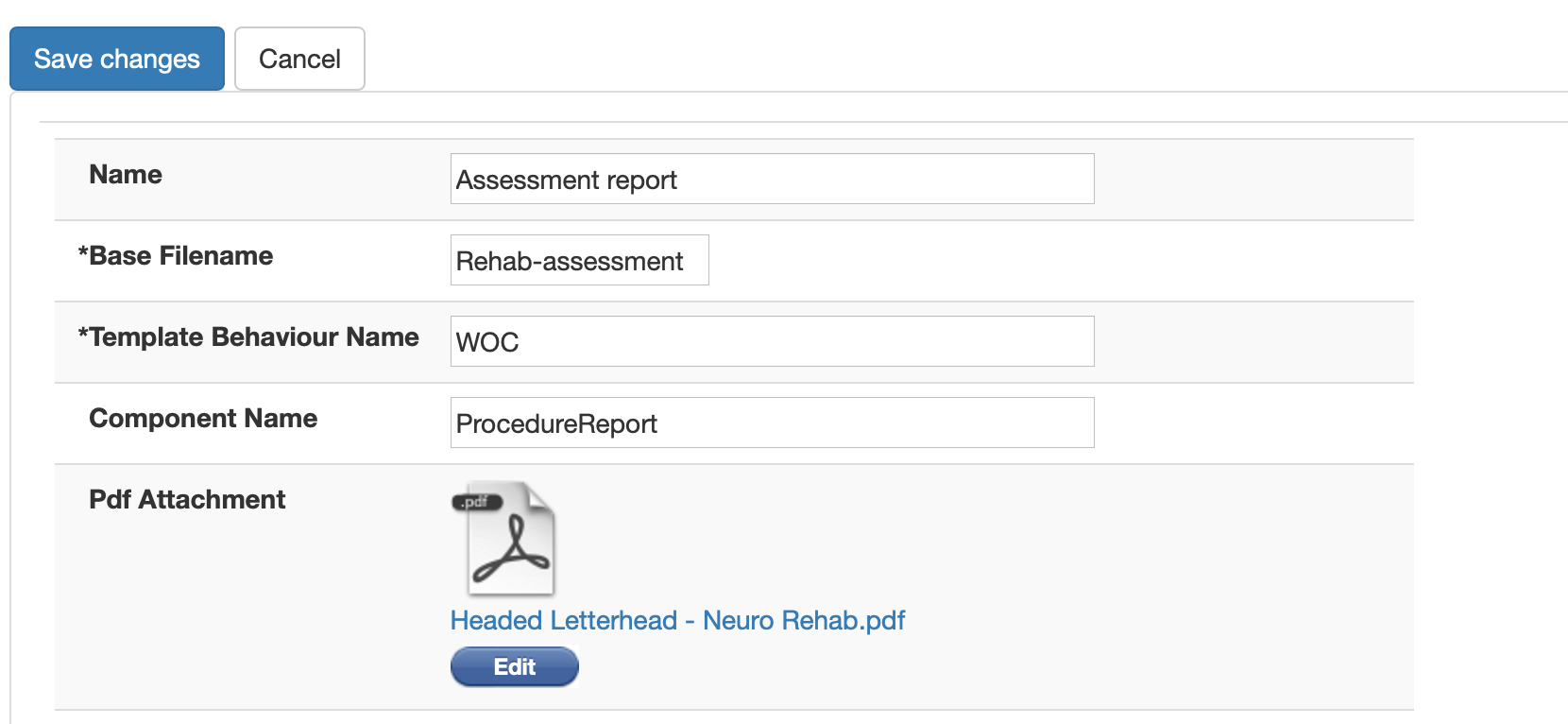
Once configured, users can create reports from their encounters.

Understanding the neuro-rehab service
But now we have those data, we can slice and dice in order to help users understand their service.
In neurorehabilitation, the team want to understand who is in their active cohort, and understand those patients who need further review, as well as identify those ready for transfer. I can configure a “home page” for each service to provide a flexible modular system to show the right information at the right time.
This is what it looks like for neuro-rehabilitation:
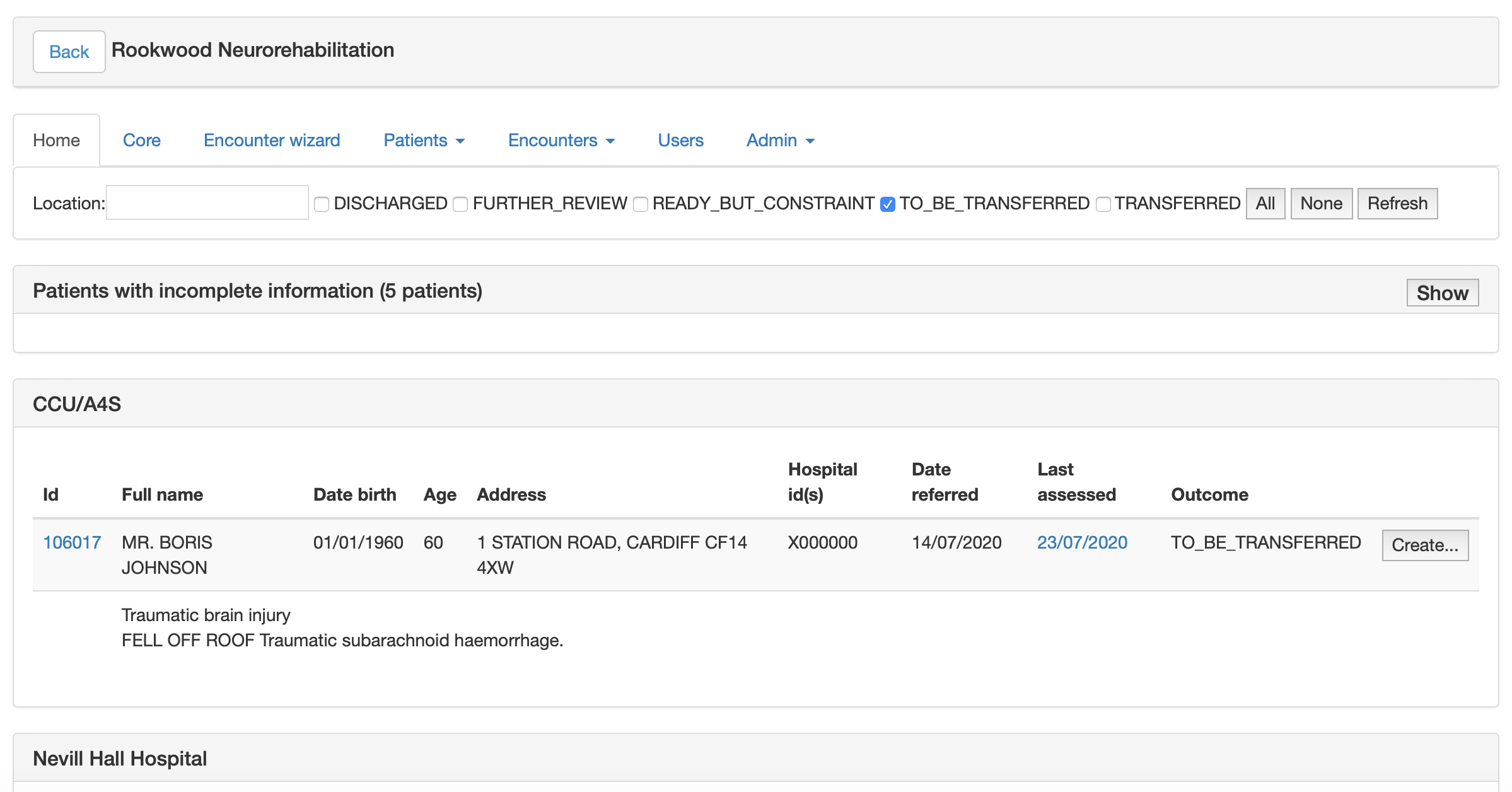
Not only do the team get to see who is in the cohort without a current assessment, but also stratify based on location and status, the screen updating as different criteria are chosen. If the team want even greater flexibility, they can download a spreadsheet of data, by default with patient identifiable information removed.
This took just about six hours to go from inception to deployment, mainly because I’m able to simply stitch together foundational components to solve specific problems.
Mark