There’s more than one side to every story
Historically, data capture in health and care has been driven by the requirements of central data returns, permitting management and government to examine and monitor a specific health policy area. Information standards are very important in ensuring organisations feed the right information back in the right format so that the data are interpretable.
An example of a data set is the emergency unit data set ( NHS England and NHS Wales)
All organisations are expected to return data on attendances at the emergency department including diagnostic category, level of triage (urgency) and onward destination.
There’s a similar requirement for outpatient clinics.
Knowing the format of the data to be returned, how it is to be coded and how and when to return data are all important but there are also rules and definitions which must be followed. That’s the job of information standards and therefore, historically, the principal customer of information standards has been central data reporting. Those users have requested standards, they’re discussed and then set, usually by publishing a ‘data standards change notice’. A new government policy or a problem affecting policy teams results in a new requirement for data reporting with either a new information standard or an update to an existing standard.
It’s easy to see the consequences in clinical practice. There are byzantine rules relating to my outpatient clinics to which I am only dimly aware and forms to fill in that have little to do with the patient in front of me and everything to do with the requirements of the wider system. They’re important, but they’re but one facet of the clinical encounter. In many situations there is considerable overlap with the needs of direct care and that of management, at least semantically, but sometimes the categories are simply too coarse or the rules don’t keep up with change.
For example, this is from the outpatient dataset definition:
“ An appointment cannot be counted unless the patient actually attends “ http://www.datadictionary.wales.nhs.uk/index.html#!WordDocuments/outpatientattendances.htm
So what has happened to the telephone appointments I’ve done for years?
Well, fortunately, an update has been made this year so that virtual reviews are now part of the submission, with three categories - ‘face-to-face’, ‘virtual with patient contact’, and ‘virtual with no patient contact’. Information technology teams will be adding these data fields to administrative systems so that these returns can be made in this altered form.
Central data requirements are important and valuable in running the wider health system but it is commonly the case that those requirements define the operational requirements and design of clinical systems instead of being recognised as simply another prism through which to view the patient record. It’s important when designing clinical systems to understand the uses of data, for all needs.
The the main issues with central data requirements as the basis to build clinical software are:
- they tend to result in the use of classification systems; using taxonomies makes it easier to perform analysis but they are a poor fit for the ambiguity and complexity of the real world
- they use bespoke, proprietary value-sets limiting semantic interoperability if they are used
- they can end up defining operational system data requirements
- they usually expect tabular data to make it easier to analyse but health and care data is rarely tabular. Patients have more than one diagnosis.
- the rules for central data propagate into clinical systems creating brittleness; it makes changing those rules difficult and skews our ability to use historic data acquired using different rules. How we analyse outpatient attendances over time will be difficult if telephone appointments were not returned before 2020?
- the brittleness and lack of adaptability infects other systems that need to interoperate, because without ontological defined value lists, its very difficult indeed to consume data from other systems without constant discussion between the teams that run different systems, creating coupling and reducing our ability to develop software-at-pace in parallel.
The answers to these issues are simple:
- we need clinical data that is granular and specific and that models the real-world and adapts to how it changes.
- we should use ontologies and not taxonomies for data capture
- we need tools to turn granular, specific data into categorical, easy-to-process data for central returns, policy-makers and other analytics
- we should apply rules and delay losing granularity as late as possible in our analytics, and apply them dynamically and declaratively while categorising data flexibly in response to changing requirements.
Specialty codes
It has been suggested that a clinical system use a list of specialties using the “standard” as defined for reporting purposes, the “main specialty” (it used to be called the ‘treatment function code’). That’s attractive, because that part of our data won’t need any transformation in order to submit those data.
But what about our clinical users? We’d like to help them find the information that they want, at the right time, and that means providing them tools to search perhaps thousands of clinical documents. While coding specialty to the reporting standard is better than free text, we’re losing granularity.
Instead, the use of an ontology, such as SNOMED CT, can solve our many needs.
For clinical users, using an ontology means we can filter for ‘neurology’ and show ‘neurology’ letters and also ‘paediatric neurology’, while the latter will also show up in our ‘paediatric’ filter, because the ontology is more than a list of codes, as it represents the relationships between those codes. Our software can use those declared relationships to extract meaning from codes, even for codes that didn’t exist when that software was written.
Likewise, we can exchange information with other systems that do not keep up with the DSCN and we don’t need to keep orchestrating updates to the ‘fixed’ specialty list across all components, whether developed in-house or provided by third-parties, because using an ontology provides dynamism and adaptability. I can write software now that can process specialty codes not defined at the time I wrote the code. We create the right conditions to decouple our systems and create inherent flexibility and adaptability.
Decoupling is important. It may be that a new departmental system already supports the DSCN; after all the list is defined legally by the General and Specialist Medical Practice (Education, Training and Qualifications) Order 2003 and European Primary and Specialist Dental Qualifications Regulations 1998, but if not, that commercial partner will need to implement those codes. It can make procurement more difficult and more costly and fossilises the interactions between systems.
The single patient record.
Our aspiration should be the single patient record, a multifaceted longitudinal structured record.
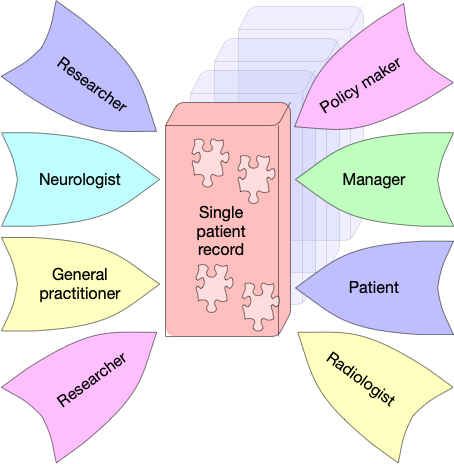
We must be clear that such a record can be used for a variety of purposes such as direct care, service management and improvement as well as research with the appropriate consent. The best way to design such a record is using highly granular, clinically-meaningful approach to data modelling based on open standards.
But I think it’s a very good idea to imagine multiple prisms through which we can see and understand that record.
Those prisms are dependent on your processes, workflow and needs. A patient viewing their own record needs a different prism than a civil servant modelling future emergency unit attendances. We should be annotating the results of investigation or groups of investigations with our clinical interpretation in the context of the problem at hand, just like we do via a letter at the moment. That data will need to be prioritised within the patient prism.
Similarly, a radiographer about to perform an MRI scan needs a different prism than a neurologist in a video consultation with a patient and family members.
Same data, different prisms. Different focus.
In the future, I hope that adaptable focus will help me identify what’s important and what’s not, but for now, ask any professional and they’ll tell you what’s the critical information they need in a given context.
So there’s always more than one side to every story.
So what?
So that’s why we need data and tools that make it easy to:
- Model the real world, capturing granular, specific, meaningful information
- Turn such granular information into categorical information for ease of analytics
- Resolve, infer meaning from and map identifiers between different systems, classifications and ontologies
And that’s why I’ve been building open-source software to solve these problems:
- go-terminology : If I make a diagnosis of acute disseminated encephalomyelitis (ADEM), I need my clinical system to record that specific granular diagnosis but I also need tools need to be able to categorise that diagnosis without manual intervention for service level analytics. go-terminology provides both of those capabilities using SNOMED-CT, an ontology.
- janus : a data-driven dynamic identifier resolution and mapping application programming interface / knowledge graph navigator.
- concierge : a backend to identifier resolution and mapping services providing integration and abstractions with multiple NHS Wales services including multiple patient administrative systems, the national enterprise master patient index, the staff directory, staff authentication services and document repositories
- clods : a backend identifier resolution/mapping service for UK NHS organisational data services and other reference data including the NHS postcode database and general practitioners across the UK
Together, these services can dynamically resolve and map between different identifier systems helping software (and humans) ‘make sense’ of health and care data.
It’s why I’ve been advocating this approach within health and care in Wales for a long time.
Mark

PS. Janus is the Roman god of beginnings, gates, transitions, time, duality, doorways, passages, and endings.
PPS. When will clinical systems build a source of open data relating to how users interact with their software in a given context in a given patient with the problems, past and scheduled events, medication known in order to learn the information value of our health and care data for decision-making? That kind of learning is just another prism, of course.