Consent-driven distributed master patient index 1/2
I would like to introduce the concept of a consent-driven distributed master patient index.
Many healthcare organisations already use master patient index software in order to try to integrate multiple disparate applications but my suggestion is that we update this concept for the Internet-era.
In essence, we need to build a distributed and open system in order to provide resource location and authorisation services, driven by consent:
- Existing enterprise master patient indices (EMPIs) provide matching and linkage across systems within an enterprise.
- We are already seeing a move to open platforms underpinned by modern information and technical standards.
- We will need to federate data from multiple providers to create a consolidated health record for an individual citizen.
- Such federation across platforms will require functionality to support resource location, so that the consolidated view includes information from any healthcare providers involved in that citizen’s care
- That consolidated view may not need to contain personally-identifiable information for many purposes but even when de-identified or aggregated, it is possible to re-identity individuals. There is a identifiability continuum with re-identification risk proportionate to the number of different types of health and care data that form the consolidated view.
- Citizens need appropriate tools and support in order to make their data sharing wishes clear and will need to be able to make their preferences clear for a range of different purposes.
To solve this, I suggest that we need a consent-driven distributed master patient index.
1. The enterprise master patient index (EMPI)
An enterprise master patient index (EMPI) acts as a consistent up-to-date registry of patient information across multiple systems, allowing matching and linkage across those systems.
The design of such a system derives from a historic use of individual healthcare applications that maintain their own patient indexes and need to be integrated with others. Those applications would usually store their own indexes in their own closed, proprietary backend storing the individual patient data against a local case record number.
An EMPI acts to link these disparate applications by matching patient demographics and as a result, can derive a list of identifiers for any given patient in any of the applications across an enterprise. EMPI products, such as IBM’s Initiate, generally use HL7 v2 messaging in order to provide lookup and matching services.
2. Platforms and commoditisation
I truly believe that we are at the cusp of a revolution in healthcare information technology in which we will adopt Internet-era thinking and technology to support the transformation of healthcare. This transformation will permit a renewed focus on the needs of individual citizens and their caregivers, and how our services are designed to meet those needs.
One of the biggest changes will be the spread of open platforms providing multiple components with standards-based application programming interfaces. Initially, these components will be part of a wider organisation-centric electronic health record system (e.g. https://code.cerner.com/), but, we will quickly see many components becoming commoditised and provided via cloud-based platforms (e.g. https://cloud.google.com/genomics/).
This scenario playing out is shown in this Wardley map:
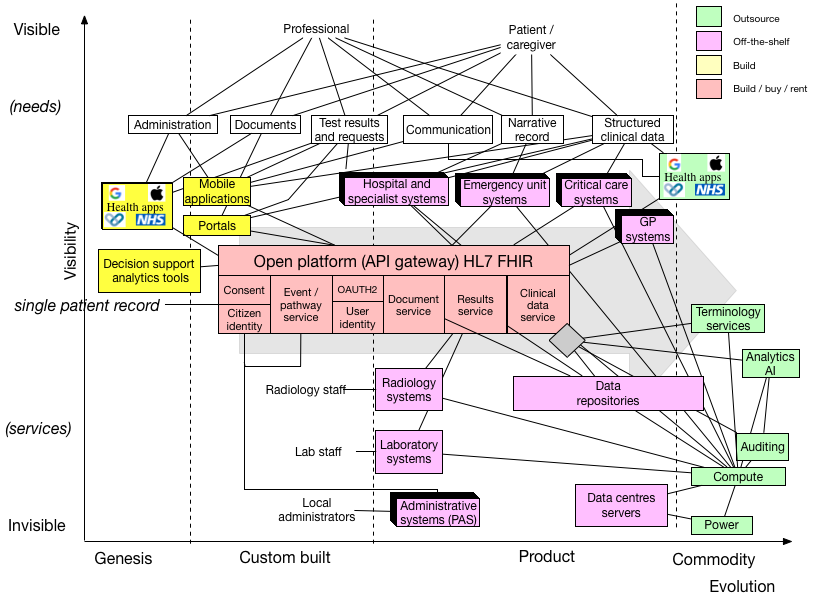
We must recognise that several components of this architecture already have well-established solutions and are best bought or rented but that other components are, as yet, unknown and need more work in order to understand the best way to design, build and deploy.
For example, we still have procured and installed locally software like radiology systems (Picture Archiving and Communication System - PACS) but even some of those could be provided as a service instead. For example, in Aneurin Bevan Health Board, they are using DrDoctor services for patient communication prior to outpatient clinic visits.
In parallel with this modularisation will be the move towards separating application code and logic from the data and its representations. As a result, we will have a new marketplace of new components will appear providing discrete computing services on-demand, making use of open data standards and readily available open-source tools to implement those standards. For example, could discrete computing functionality be provided to perform monitoring for acute kidney injury (AKI), currently using the state-of-the-art national AKI guidance? Similarly, could such an architecture permit the parallel testing and evaluation of new implementations of AKI detection before more widespread adoption?
As such, it is likely that the data and the application code (logic) will separate and themselves distributed as a modular architecture founded on open standards.
3. Federation and caching
Federation is the process in which we can build a unified single view of data from across multiple distributed information systems.
For example, a federation service might take a request for information about a patient, decompose that query across multiple source systems and return a unified composite view. Federation may combine the same or different types of data from multiple systems.
Federation might simply directly pass on a query to multiple source systems at the time of the request; such an approach might be fine if each source system has predictably high levels of performance. Alternatively, it may instead implement a vendor-neutral archive updated from multiple source systems as they themselves are updated, providing a performant cache of information updated from source systems. Indeed, one might implement federation as a combination of both; in essence, federation provides a consolidated view across multiple systems.
4. Resource location
Federation is dependent on appropriately locating resources for patients across a range of providers.
Apple have built a federated health records service to iOS via the Health app and associated application programming interfaces. This now provides a consolidated view of data from multiple healthcare providers in the United States, making use of the increasing available of data via HL7 FHIR. To do this, health providers must specifically link with Apple.
Google DeepMind built a federated records service to support their Streams app, providing a consolidated view of legacy data held within one organisation but across multiple sites and multiple software products. Those data populated, via HL7 V2, are stored in a modern archive for performance reasons and made available via HL7 FHIR.
In both, I understand that resource location is centrally managed, requiring registration or bespoke integration.
Any distributed system needs to be able to offer accurate and performant resource location, much as the domain name service (DNS) for the internet provides distributed conversion of user friendly domain names into numeric addresses.
5. Privacy and identifiable data
In many situations, such as providing direct-care such as an outpatient clinic, professionals benefit from being able to access identifiable up-to-date information. In other situations, such as when we are planning services to meet the needs of a population, it is sufficient to simply process de-identified information. Using the least identifiable information for any given given purpose is a core principle of sound data governance.
However, there is a spectrum of identifiability with fully identifiable data at one extreme and aggregated statistics about a populations of patients at the other. With aggregate statistics, re-identification is much more difficult, but is possible when numbers of individuals with a set of characteristics are small. With de-identified patient-level data, re-identification is possible and becomes increasingly possible proportional to the quantity of linked data.
For example, you could not re-identify an individual if all you knew was that they were a neurologist. If you knew they lived in Wales, then you can narrow down the possibilities. A neurologist, from Wales interested in information technology. You’ve re-identified me. Probably.
One way of trying to de-identify information is to simply replace all personally-identifiable information with a pseudonym, a random identifier. However, if all data on an individual is given the same identifier, the re-identification risk is higher than if only a single type of data is available. As such, we can augment de-identification by splitting data and giving each split a different identifier and permitting the creation of a dynamic consolidated view of data across multiple systems using multiple identifiers by virtue of a variable degree of linkage.
For example, Google Maps will track route journeys for traffic analysis, but reduces the privacy impact by splitting up the journey into smaller sections, each with a different identifier. Your progress during those sections is recorded to help others, but no-one is able to recombine those data to find out from where you travelled. Anonymisation occurs because there is no linkage from your identifiable information (your account details) and the traffic identifiers. If Google kept a record of your account and the identifiers used to track your journeys, then conceivably your journey could be recreated and your data has only be de-identified.
In addition, it is possible to further limit the risk of re-identification by deliberately adding noise into datasets so that aggregate statistical analyses give the same results as the original source data; such an approach is called differential privacy.
As such, we can work to protect privacy by both controlling the linkage of data from different sources as well as deliberately adding noise into data when aggregated and shared.
6. Consent and health data
Health data have three broad purposes:
- for direct care of an individual patient
- for supporting and running services by aggregating individual-level data at the level of an organisation, service or cohort in order to monitor and improve services for those patients
- for supporting research
There are more detailed examples at https://understandingpatientdata.org.uk/why
Not all health data are the same. For example, information relating to sexual health, termination of pregnancy, genetics, mental health, substance abuse, employment issues and stigmatising social data may, at the discretion of an individual, be considered quite differently from other health data.
Pharmaceutical companies and clinicians are interested in assessing the real-world outcomes of their treatments and projects like the Clinical Practice Research Datalink (CPRD) demonstrate the usefulness of this post-marketing surveillance.
Consent may be opt-in or opt-out and given implicitly or explicitly. When you sign up to a clinical research project, you must opt-in. When you don’t want your health data shared for secondary uses in NHS England, you can opt-out. When you attend a hospital and extend your arm in order to let someone take your blood, you have given implicit consent. When you sign a consent form for your appendicectomy, you give explicit consent. When you attend hospital unconscious and we work to treat you, we are working in your best interests. When your advance decision to refuse treatment (ADRT) states that you do not want cardiopulmonary resuscitation, to perform that act would be an act of assault.
The NHS England care.data project was halted in the face of widespread public criticism and loss of trust, despite the potential benefits for population health and clinical research.
One of the outcomes of the debacle was a renewed focus on building trust and obtaining consent. As a result, we must work to ensure that we organise health information to make it accessible subject to consent and control by the individual or their representative.
So what follows?
In essence, I have argued that we need a distributed equivalent of a master patient index designed for the Internet-era and driven by consent.
This index needs, itself, to be distributed and federated, and yet designed to protect privacy. My next blog post in this series touches on some of the potential technical standards and services required to support such a system.
Mark
PS My previous posts on pseudonymous consent and associated code were an experiment solving some of the issues that I’ve finally got around to documenting here.