Mapping the electronic health record 2/2
This is part 2/2 of my presentation at MapCamp 2021.

You can watch a video recording of that presentation if you like, but this post is a deeper dive into some of the detail.
2. Algorithms
So what about algorithms, and machine learning in health and care? Are you sure machines need anything different to what we as humans need?

I’ve previously drawn Wardley maps for the use of algorithms and machine learning in healthcare:
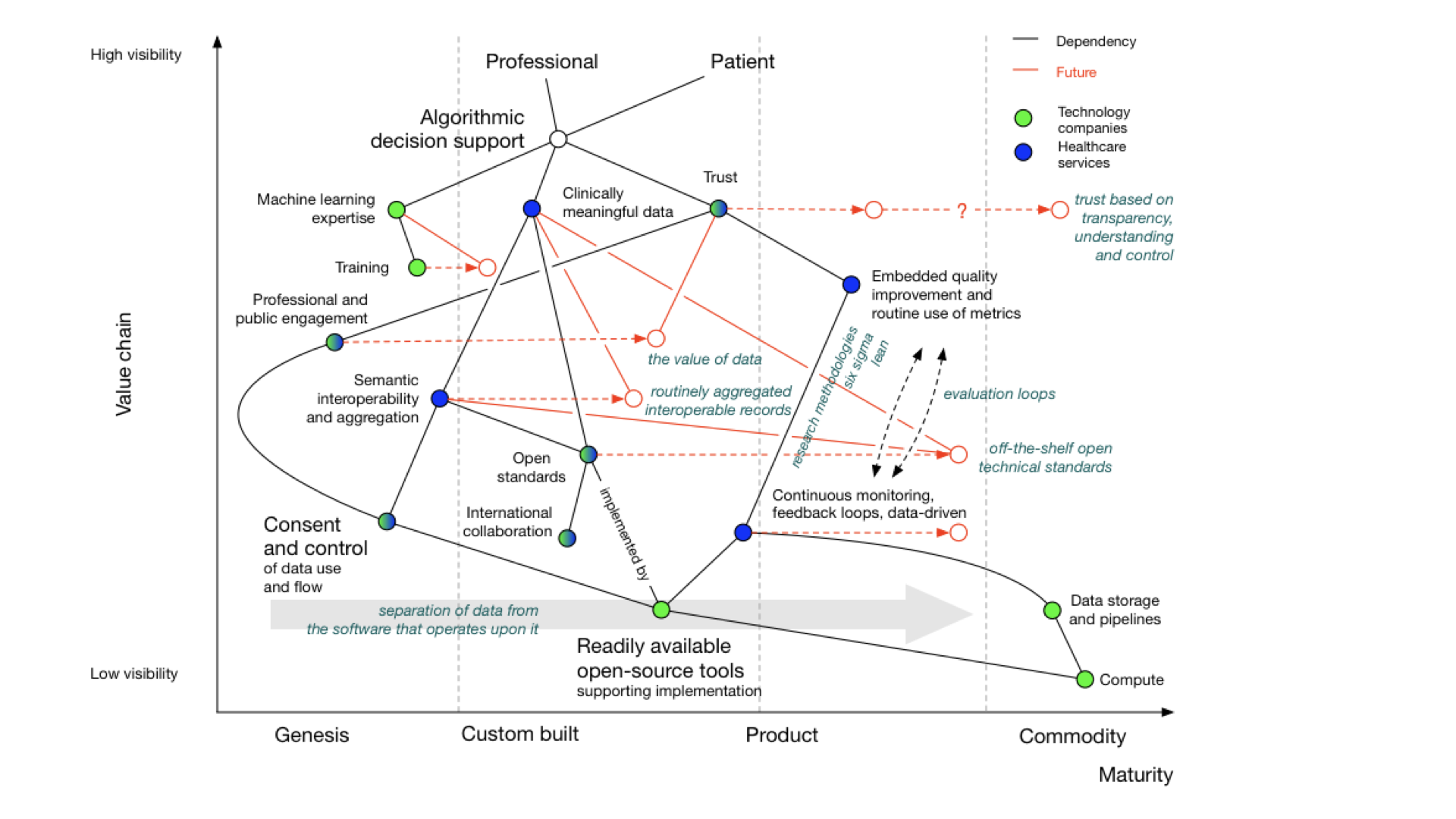
There’s a complete blog post about it, if you want more detail.
But, you’ll see that whether you are looking to support a new clinical score that calculates stroke risk, or a new machine learning algorithm that can interpret chest x-rays, computers need the same types of information and support and feedback loops and monitoring as do professionals and services and facilities.
Our Wardley map shows dependencies on:
- meaningful data
- feedback looks
- monitoring and evaluation pipelines
- consent and control
- readily available tools and libraries
What do we currently have?
This map looks at the electronic health record from the viewpoint of an organisation, because that’s the usual model of how software used in health and care, whether for acute hospitals or community services.
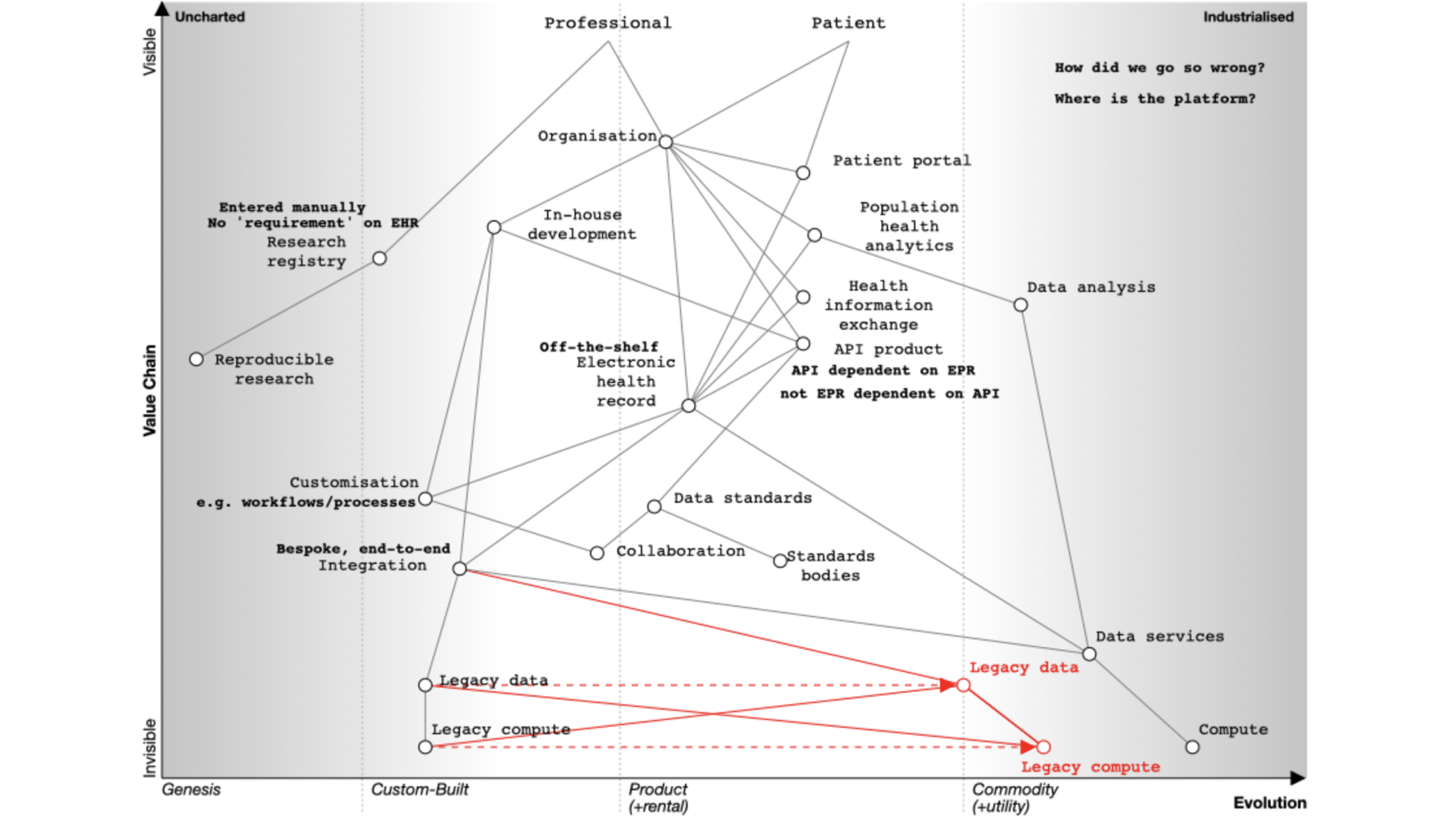
In this map, I show a dependency from the organisation to an electronic patient record.
NB: I think that dependency and mapping from organisation to health record can and should be challenged. A patient shouldn’t have to know that one specialist service is managed by that organisation and another from another; aren’t they interacting with a health service that should feel seamless? They should not need to know organisational or department structures. We need to move to a single logical patient record, even if that record is aggregated or federated from multiple providers.
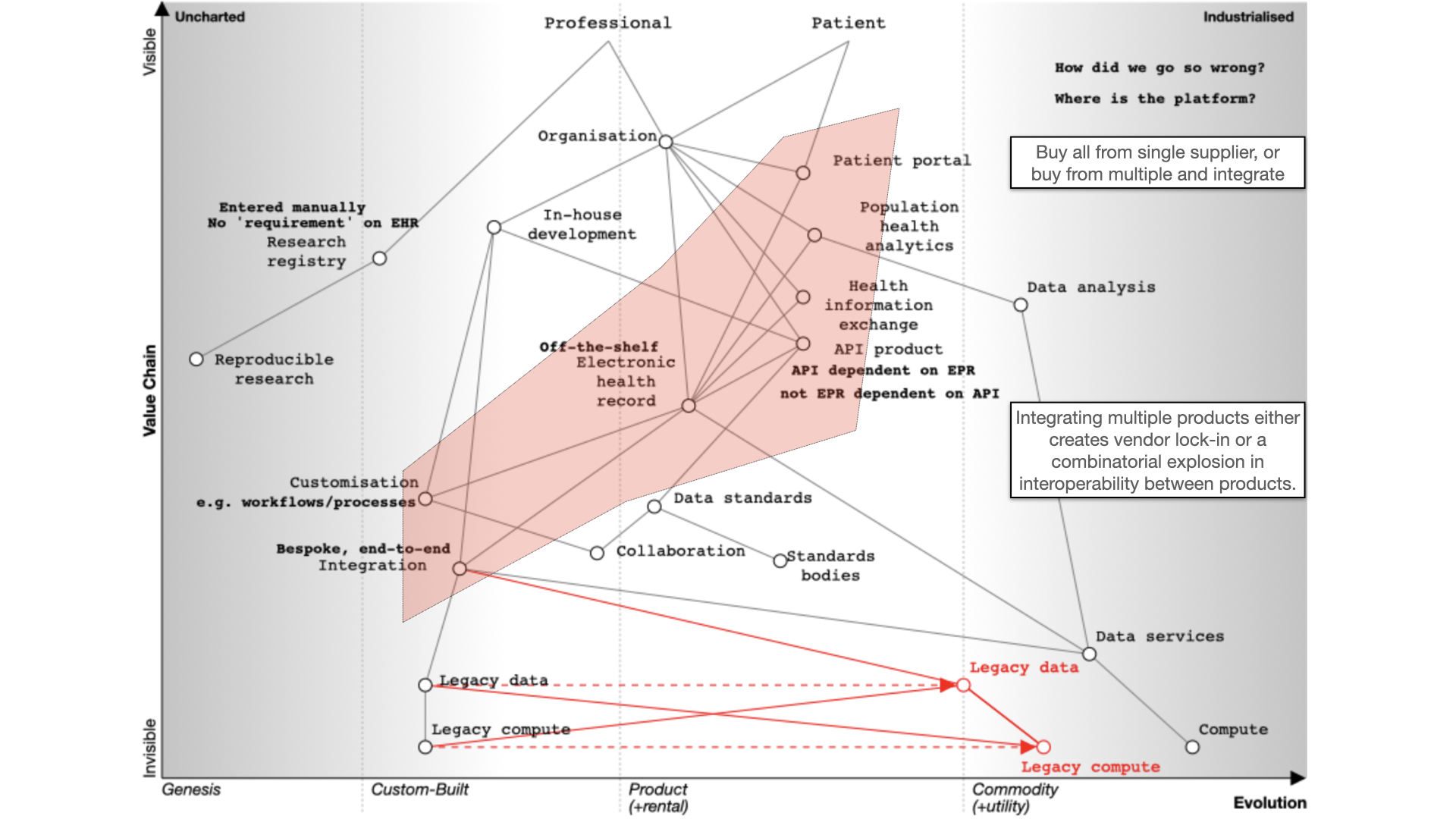
Many organisations have bought off-the-shelf electronic health record products. As part of that, they might also buy, usually but not always from the same supplier, the following products:
- a patient portal - to allow patients to interact with, or at least view their record, at that organisation
- population analytics - to allow analytics across groups of patients
- health information exchange - to share data between organisations in, for example, a region
- an API product - to allow developers to build products using the data and services within the EPR.
An API is an “application programming interface” - in essence a way for systems or subsystems or modules of software to communicate.
You’ll see from the map that the API product is usually dependent on the EHR in this model. We’re going to need to challenge that, because health and care records should surely be built using open APIs, not the other way around?
How can it be that our APIs our dependent on the EPR, rather than our EPR being dependent on our APIs?
In addition, the organization wants to share data across a region so they buy the product’s linked health information exchange (HIE) product. This means that they can exchange data with other hospitals and other organizations within that region.
But far from reducing the need for in-house development capacity, the need for integration and customisation means many organisations embarking on their EPR journey end up increasing the numbers of in-house developers. The EPR, costing rather a lot of money, hasn’t really solved all of our problems at all, and what we think of as research remains entirely separate. It is akin to thinking we’ve bought an ‘off-the-shelf’ suit, but actually needing to do a significant amount of tailoring ourselves.
Importantly, spending this money on an EPR does not prevent us having to do some real work on proper collaboration and cooperation across health and care whether it be for direct patient care, service management, improvement, monitoring or research, for otherwise we still end up with data silos in which we cannot easily pool data. Indeed, we surely need to prioritise that work rather than thinking we can defer until after our EPR deployment?
Dependencies, and tell me again why are we building our own data centres?
Our map also shows us that our in-house development, our EPR, our analytics platform, our health information exchange, and patient portal(s) need infrastructure on which to run such as ‘compute’ and ‘data’ services. However, the map shows that health systems still have significant legacy services that are bespoke and proprietary and custom-built, instead of recognising that, particularly with limited local resource, we should be focusing on the things only the public sector can do, and using off-the-shelf infrastructure on demand.
The big technology companies have so far pretty much failed in healthcare. I give them a D- “Could do better”.
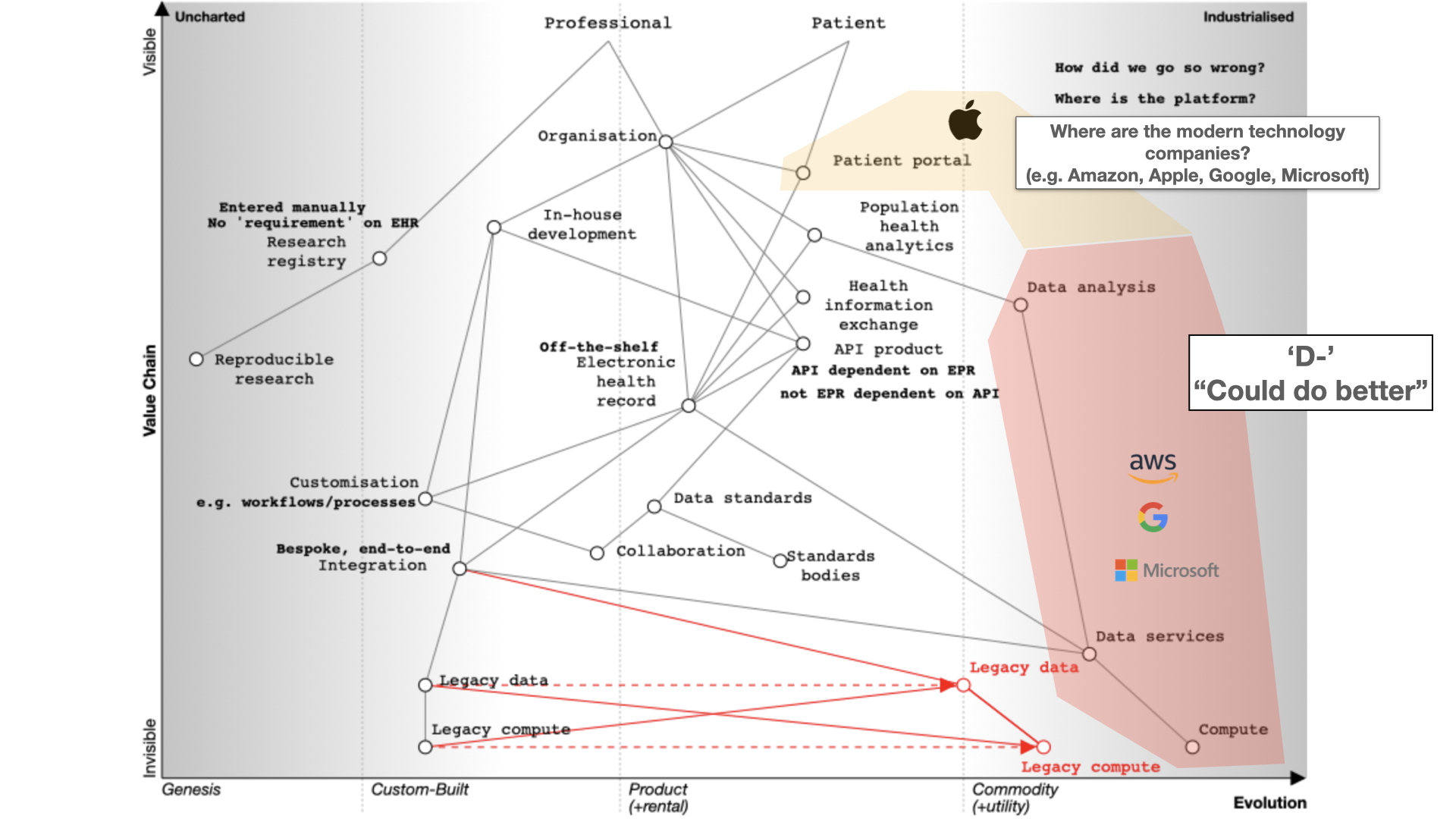
They’re fixated on infrastructure, particularly cloud services. Apple is an exception with its Apple Health app serving as a patient portal.
The fundamental question for electronic health records (EHRs) is whether to buy from one vendor or assemble a best-of-breed system, both of which can lead to complexity, particularly if we use point-to-point integration patterns rather than a common shared platform. Buying the components from a single vendor, or integrating best-of-breed can result in a fossilised architecture which is difficult to change, proving to be inflexible and difficult to adapt to changing requirements. There can be a combinatorial explosion unless we build a platform on which disparate applications and services can sit.
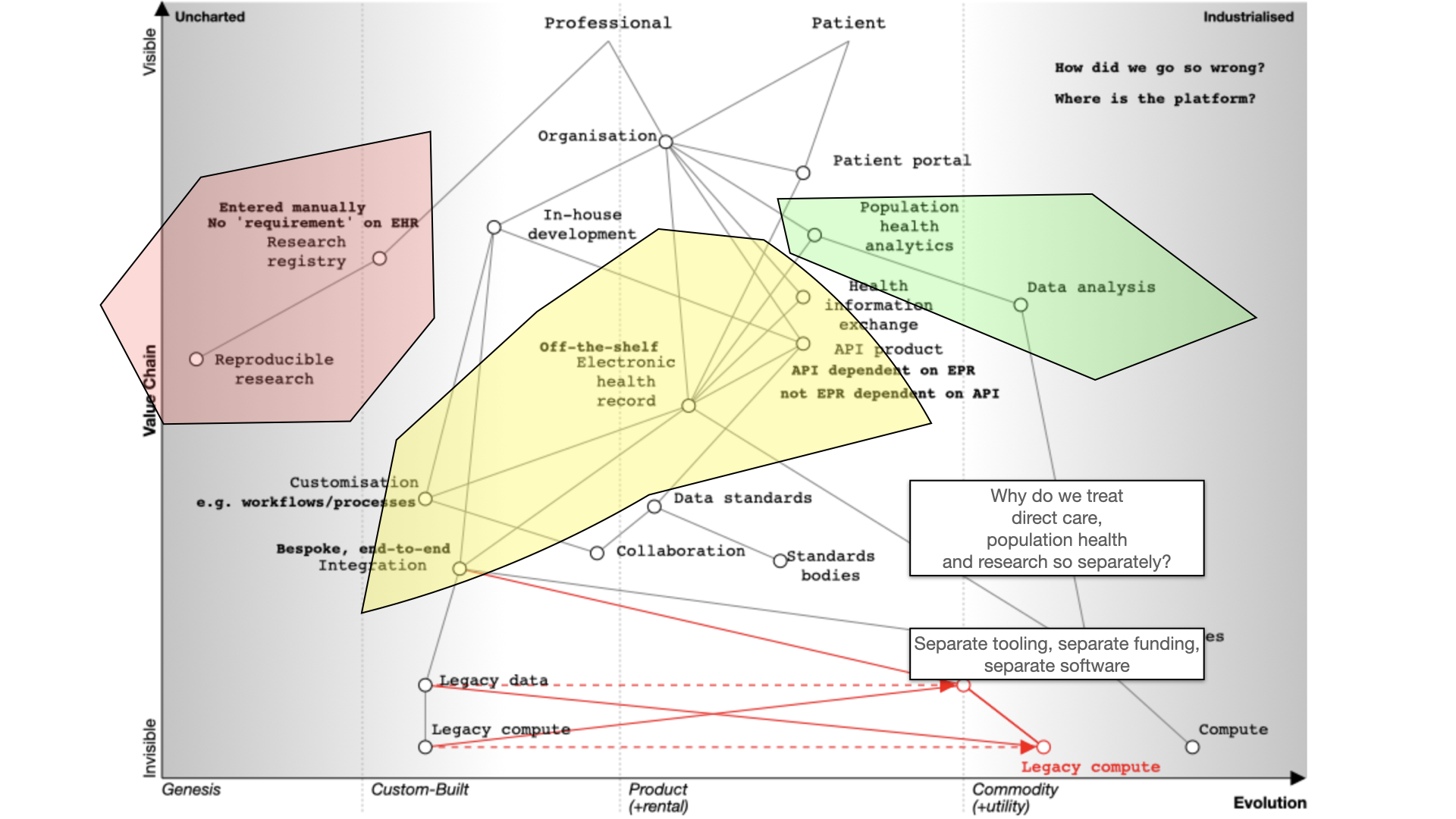
Finally, we should also ask why are healthcare data for analysis, research and direct care kept separate? They should be integrated for better patient care, with the same data used for multiple purposes. For example, direct patient care can surely be aided by real-time analytics - I’ve previously shown examples where my own EPR has plotted disease outcomes over time for a single patient compared to an aggregated dataset of similar patients to aid shared decision making and understanding.
Many of our issues in health and care are cultural and historically. Why do we use different programming languages and data stores for analytics and EHRs and therefore hindering progress. We need to challenge these assumptions while embracing standardization and mapping of data. Why are we standardising applications that are difficult to integrate, rather than standardising our data?
What do we need?

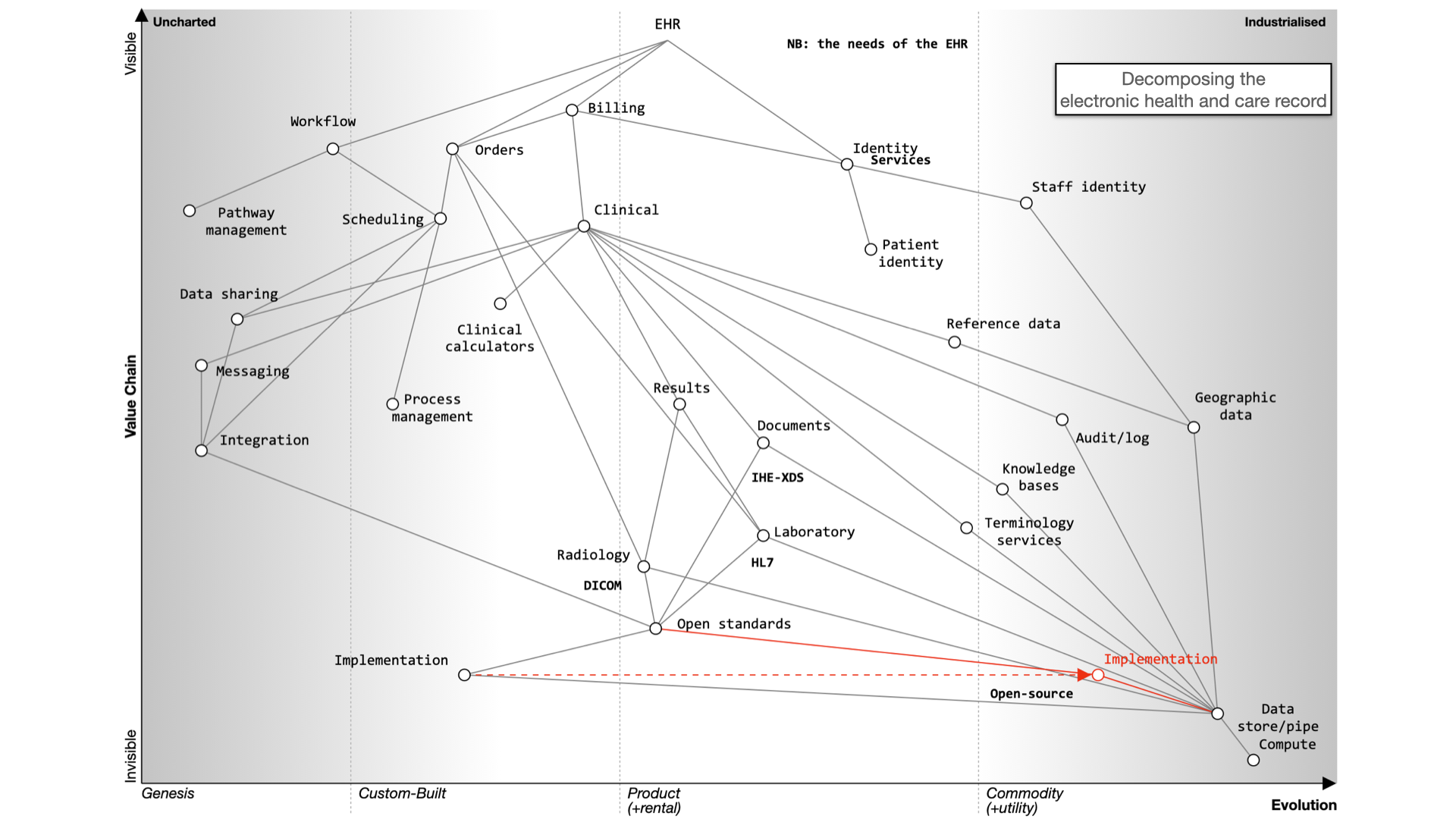
For EHRs, you can choose a monolithic system like Epic or Cerner, which handle billing, clinical data, identity services, and orders. Workflow support is lacking and clinical calculators are often proprietary. Data sharing is challenging and should be standardized.
Decomposing the electronic health record
Here’s what happens when we buy a monolith:
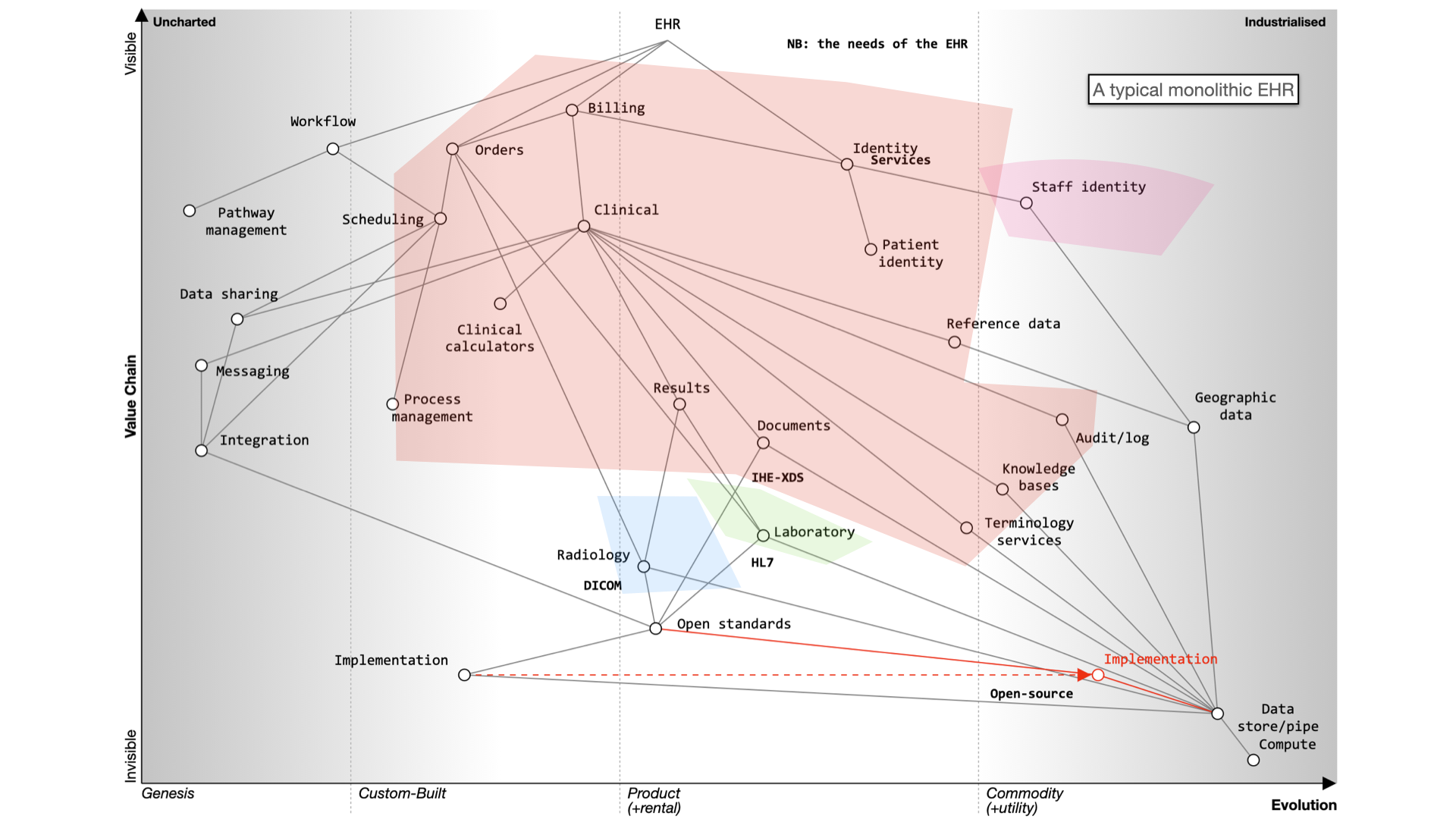
It still will need to be integrated to a PAS, to radiology and likely a separate laboratory management system. It may even not be a monolith itself - for example, Cerner’s EPR is actually a combination of a number of different products made to look like a single application.
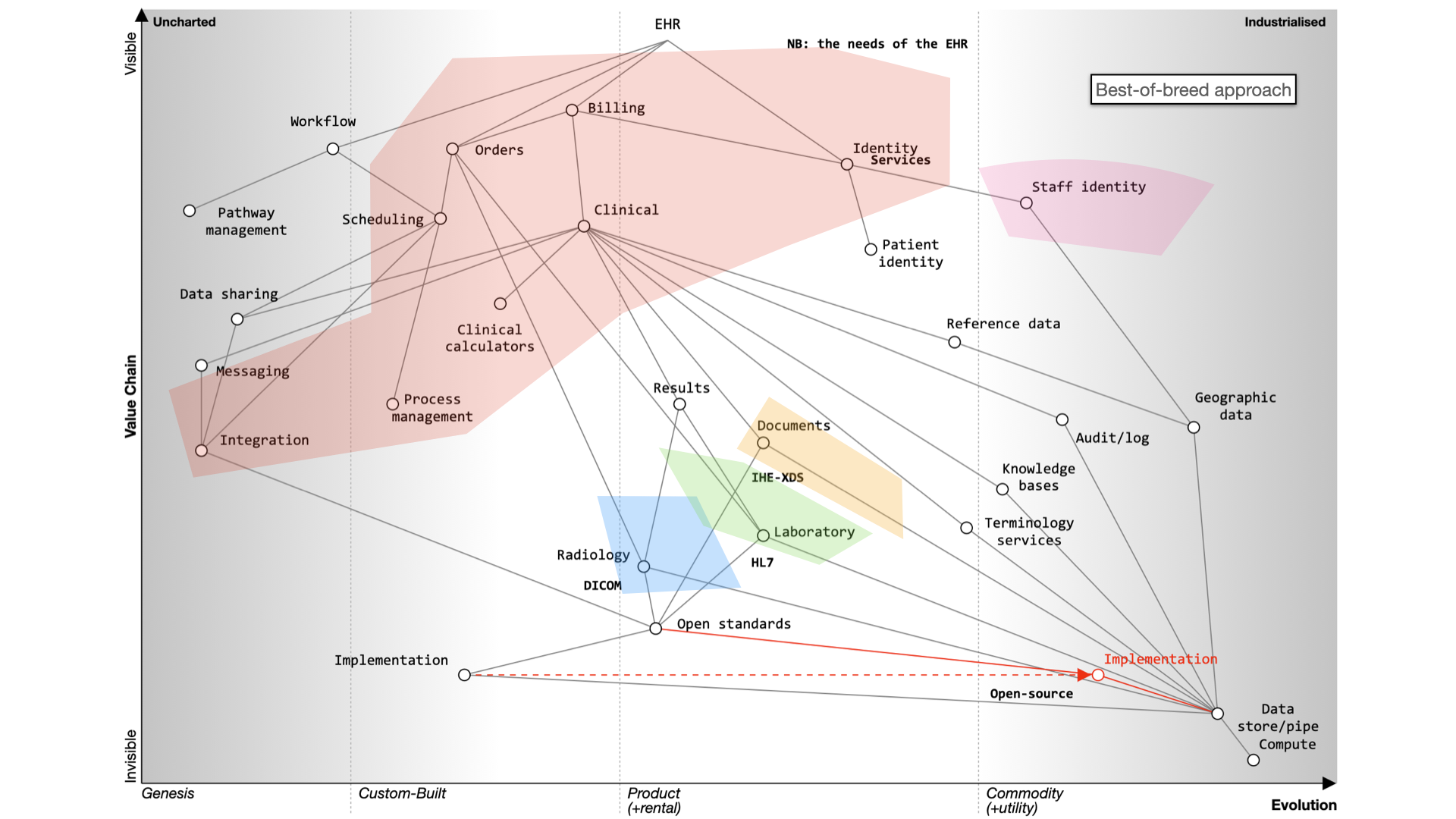
Alternatively, a best-of-breed approach allows you to integrate various systems, but it’s complex and custom and potentially difficult to flex and adapt in the future.

Instead of focusing on the needs of an EHR, we should prioritize user needs, including researchers, clinicians, and patients. Decision-making relies on evidence, communication, and action. We lack sophisticated decision support tools and meaningful data, often siloed within organizations.
To improve healthcare, we need to share data securely, enhance trust, and implement open standards. Workflow management and process orchestration are vital. Users should control their data with advanced technologies like secure enclaves and homomorphic encryption.
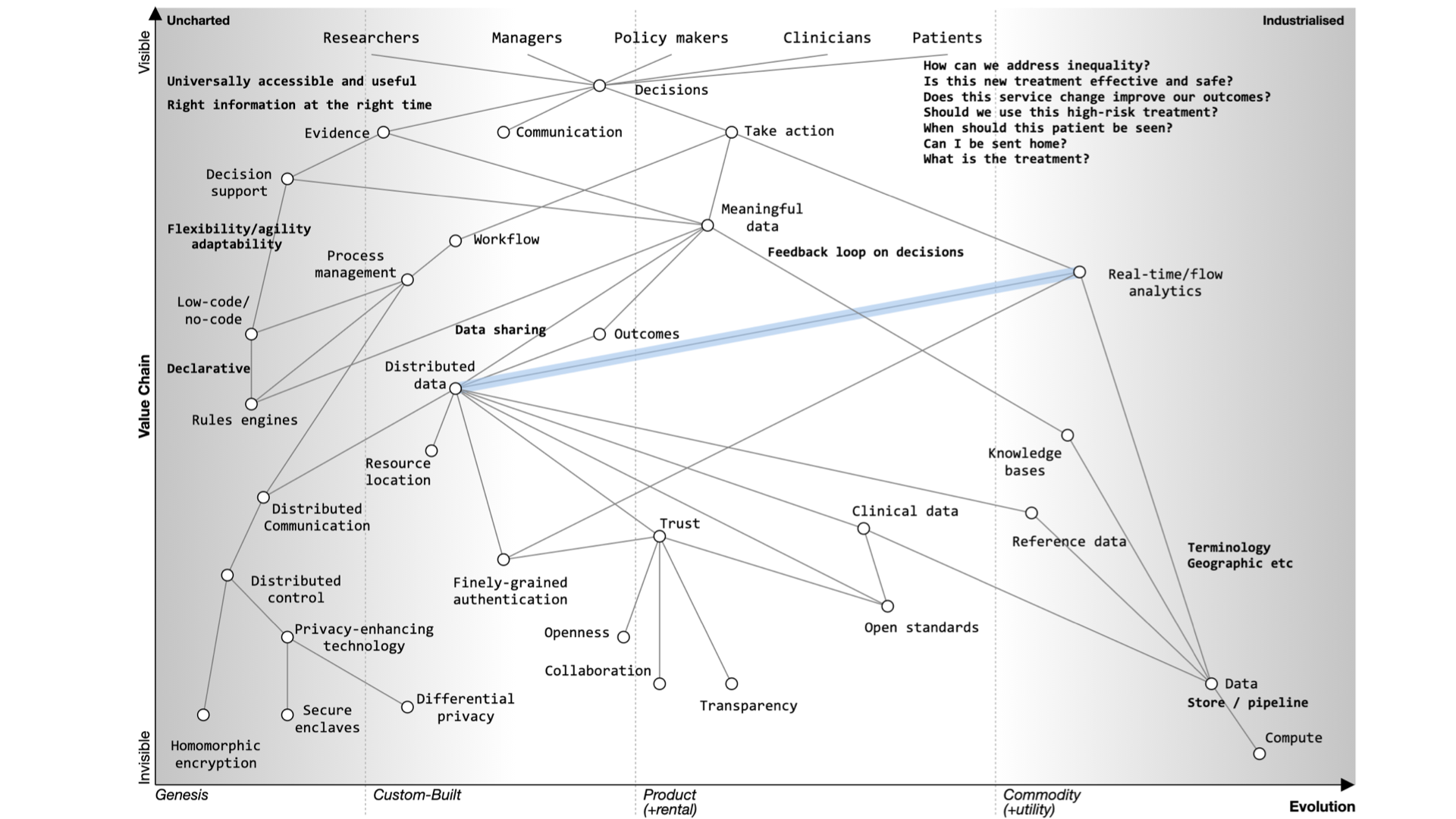
Foundational services should be open and standardized, focusing on clinical data, reference data, and commodity compute providers.
In the future, we should aim for user-centered applications, trust, and outcomes. Transparency, collaboration, and openness are key principles. Open source should drive the adoption of open standards.
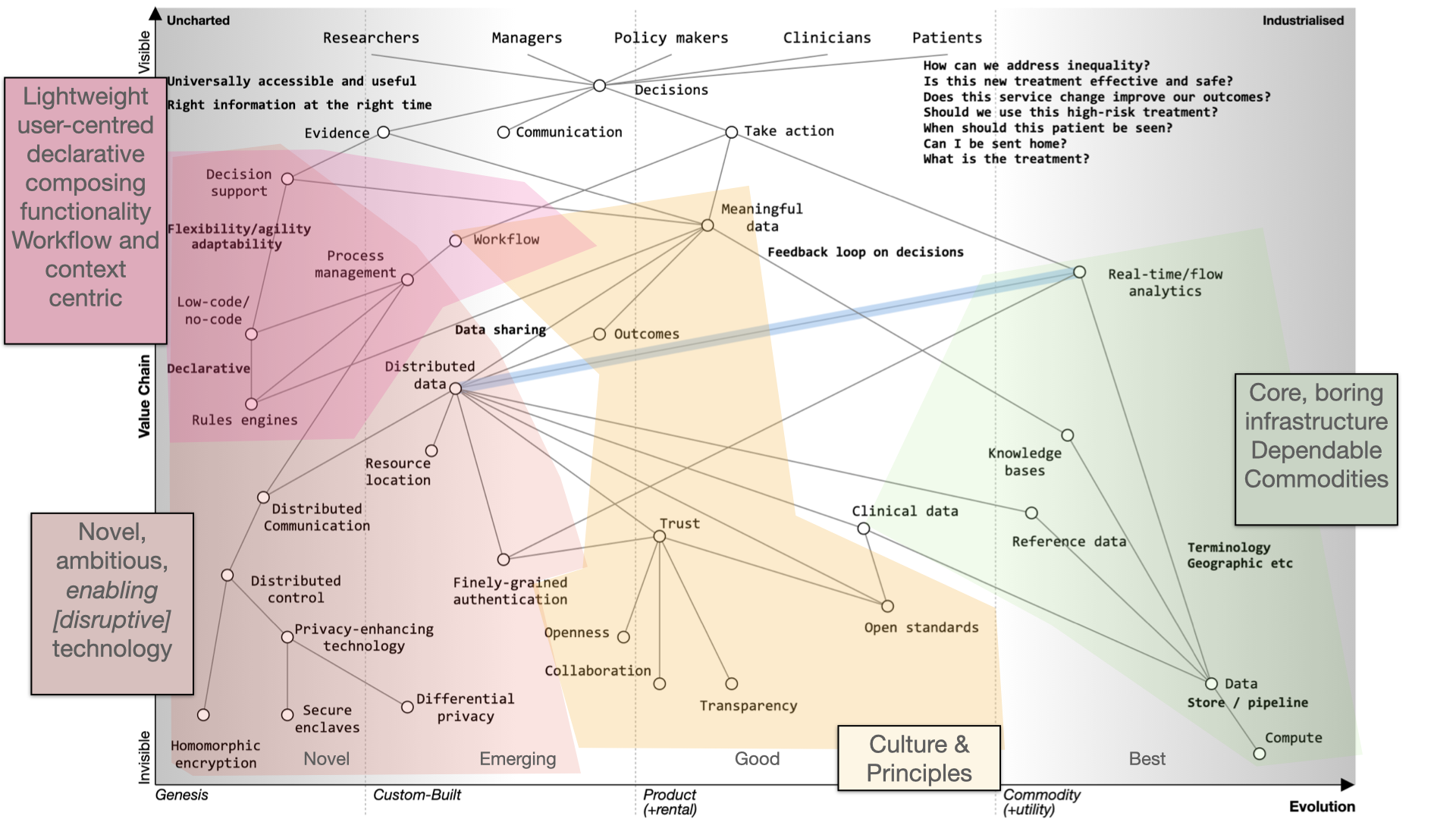
Modern technology companies should view the cloud as more than a data center relocation, leveraging its potential for healthcare. This shift can disrupt the existing market, emphasizing value and patient outcomes.

Thank you.