Jekyll2023-10-19T22:09:30+01:00https://www.wardle.org/feed.xmlHealth informatics and information technologyby Dr Mark Wardle, Consultant Neurologist and Chief Clinical Information Officer (CCIO)
NHS data: we have a problem2023-10-19T20:19:19+01:002023-10-19T20:19:19+01:00https://www.wardle.org/strategy/2023/10/19/nhs-dataIf you’re in clinical informatics, you can learn a lot from the COVID-19 pandemic.
When we needed to send out shielding letters to our patients with motor neurone disease,
I ran a report against our neurology electronic patient record, obtaining the
names and addresses of all of our patients with motor neurone disease in South Wales.
In generating that report, each patient’s vital status was automatically checked with multiple
authoritative sources of information, to ensure correct address information and
to ensure we would not send a letter to a patient who was deceased.
This was straightforward because a) we had coded diagnostic information and b)
we had a sensible and flexible information architecture that minimised manual
effort. It took me about 10 minutes.
When we needed to send out shielding letters to patients with multiple sclerosis
but only those on certain categories of disease modifying drugs, then I ran a
report against our neurology electronic patient record as above, but simply
added a cross-reference to the active medications we had recorded.
This was also straightforward because a) we had already coded both diagnostic
and treatment information for our entire cohort, and b) we had a sensible and
flexible information architecture.
For both, the use of standards such as SNOMED CT and dm+d was critical in
creating meaningful data that could be used for a variety of purposes, such as
direct care, service management, and research.
When patients receive botulinum toxin in our clinics, we record using our
electronic patient record. A document is sent into multiple portals and the
structured information behind that document is stored, so that we know exactly
what brand, dose and even where has been injected, all using SNOMED CT.
The document is useful, but the document is simply a side-effect of the data.
So what about NHS Wales?
But in the wider NHS Wales, there were significant data problems, not least
errors in getting the correct address for patients.
And our national ‘portal’, the ‘Welsh Clinical Portal’ is little more than a
document and results archive. Many aspects are good, such as being able to see
letters and laboratory and radiology results from across Wales, but we should
have much greater ambitions. This is software that has been in development for many
years and yet is a long way from being an electronic patient record.
It’s time for a reset.
NHS Wales needs to become data-driven.
We need to be able to focus our limited resources and manage the backlog of
patients waiting by the sensible and considered use of clinical data in order to
prioritise, minimise harm and improve outcomes. We need greater user-centred
design, and clinical leadership, not ‘engagement’ as the last part of a development
process in which the first time we see a new design it is about to be launched.
The Welsh Audit Office (WAO) highlighted a “lack of independent scrutiny” and
“unbalanced reporting of progress”. We as an informatics community should be
much more open and transparent on the challenges we face, and turn our expertise
to meeting those challenges.
Mark
]]>Pluripotent data: A data strategy in health and care2023-10-03T04:03:03+01:002023-10-03T04:03:03+01:00https://www.wardle.org/strategy/2023/10/03/pluripotent-data
Pluripotent data
Pluripotent: capable of giving rise to several different cell types.
“Pluripotent” is a biological term applied to cells that are undifferentiated
and are capable of differentiating into several different cell types, and
therefore satisfy a variety of demands
Therefore, I propose the term ‘pluripotent data’ for use in healthcare.
In essence, I use ‘pluripotent data’ as a way of describing the prioritisation
of data harmonisation and standardisation through common data models that may be
used, directly or indirectly, for multiple purposes to meet a variety of demands.
Principles supporting a data strategy
The key principles that should underpin a healthcare organisation’s data strategy are:
Vendor neutrality
Use of standards
Harmonisation, intermediary structures & multi-purpose analytics; pluripotent data
Specialty extensions, registries and research
Governance and transparency
Procurement, compliance and audit
Training and education
Vendor-neutrality
The current situation is that healthcare data varies between organisations and across applications and depends on purpose.
Health and care data can be used for multiple purposes such as direct care, reporting, research, service management and quality improvement.
In the main, the current fragmentation reflects organisational and governance structures - this is Conway’s Law in action.
“Any organisation that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
Mel Conway
The consequence of this ‘Law’ if that if direct care, hospital administration, quality
improvement and research are separate in an organisation, or represented by different
organisations, then the ‘systems’ developed will mirror the pattern.
No wonder then that end-users feel such significant fragmentation. This is not a new issue.
The various clinical systems, many of them paper based, differed from one another and had no relationship with the administrative hospital-wide systems. The funding made available in the late 1980s and early 1990s for medical and later clinical audit helped to reinforce this separation by making available to groups of clinicians money for small local computer systems. The lack of any connection between these different systems, one administrative, the others clinical, for collecting data cannot be explained solely on the basis of some technical or technological reason. It was just as strongly a reflection of a mindset that clinical matters were the sole domain of clinicians and non-clinical matters, to do with the management of resources and with the movement of patients into and through the hospital, were the preserve of managers and administrators.
The key thing to remember about Conways Law is that the modular decomposition of a system and the decomposition of the development organization must be done together.
The term ‘Inverse Conway Maneuvre’ (also known as ‘Reverse Conway Maneuvre’) was coined by Jonhy Leroy and Matt Simons (ThoughtWorks) in December 2010.
In what could be termed an “inverse Conway maneuver,” you may want to begin by breaking down silos that constrain the team’s ability to collaborate effectively.
Martin Fowler
While there are valid criticisms of the ‘Inverse Conway Manoevre’ relating to organisational change, it can inform our
approach to data and data flow.
In essence, rather than framing data in terms of applications, we instead focus on data. Our data is therefore vendor-neutral.
And an ‘Inverse Conway Manoevre’ looks to set up collaborative efforts than span organisational and domain boundaries
so that we build a common data model that can, either directly or indirectly, be used for multiple purposes.
In Wales, through the Welsh Technical Standards Board (which I chair) and Welsh Government, we have mandated HL7 FHIR as a foundational
standard for operational clinical systems. This is an important step to build interoperability between different clinical
systems and fosters the re-use and composition of data.
However, HL7 FHIR does not solve semantic interoperability unless one builds in mechanisms to ensure that the information
standards - the dictionaries encoding different types of information such as reference data like location, or staff member,
or patient, or value sets - are aligned.
As such, we need to be explicit in mandating the FAIR principles, so that data are:
Findable (through metadata and linked data technologies)
Accessible
Interoperable (through standards and vocabularies and collaboration)
Re-usable (through provenance and standards)
Data harmonisation
There is sometimes a tension between what we think of as general purpose healthcare data and specific demands.
For example, we contribute to a national audit on stroke care, but because we have separate clinical and dministrative
systems and this national audit, we have to have dedicated members of staff keying in information from multiple sources
manually in order to satisfy the specific demands of this (important and useful) national audit.
Instead, we need a mechanism that provides a defined patient-centric common data model (CDM) that acts as a foundation
that can be extended to suit multiple purposes. This means that, for example, two organisations can generate
combined regional datasets simply by composing (merging) their data.
This highlights two important requirements:
We need to think of our extract/transform/load (ETL) operations as first-class and important
We need to recognise the value of shared tools and knowledge in the process of data harmonisation across health and care.
For example, Welsh Government are keen to modernise the dataset in relation to outpatients. Until COVID, an outpatient
encounter was not counted unless the appointment was face-to-face, despite many clinical services offering telephone
consultations for many years. In essence, they want greater detail on scheduled outpatient care and include information
relating to procedures and problems/diagnoses.
The problem is that, at the time of writing, they cannot cope with such information encoded using SNOMED CT and instead
want categorical data - “just one of the top five categories”. This is fine for central reporting, but the team
suggested a clinical-facing application that would capture those categories at the point of care.
This is quite wrong.
Do we accept that demands for central data reporting define our clinical systems?
Certainly not.
So we must instead recognise the importance of our data infrastructure and ability to map, process and convert
structured meaningful data for a variety of different purposes.
It also emphasises how important it is that such decisions are made by people with required technical knowledge: we need
to also consider the digital and data capabilities of our health and care workforce.
Using intermediary ‘pluripotent’ data representations
In this diagram we have multiple operational clinical systems and a variety
of methods of extract and transform to our intermediary patient-centric
data representation. The OMOP CDM is a good example of such a representation,
potentially being useful for solving multiple demands, and sufficient flexibility
to be specialised easily.
From such a CDM, we can subsequently build further data pipelines permitting
more bespoke ‘rectangular’ projections of our granular and complex health data
suitable for reporting requirements or demands of centralised registries.
In this, we gain multiple perspectives, or prisms, on the same common data models.
You can read more about OMOP and their common data model here.
Requirements
A data strategy with common data models at its heart has important technical, organisational
and cultural requirements:
Strong internal governance
Registration and monitoring of data flows (information governance, feral apps, o365)
Standardisation of data across uses
Harmonisation
Understand common foundations
Maintenance and publication of common data model
Dependent on appropriate governance e.g., local clinical and technical design authorities (and their links with others)
Standardised vocabularies
Essential for semantic interoperability
Match to regional, national and international standards
First-class mapping and transformation
To satisfy myriad potential requirements - operational clinical systems, analytics, reporting and research
Openness and transparency
Radical transparency and visibility; working in the open
Publication of standards used, for all purposes. Openly available and managed and updated
Versioning and registration of use
Avoid breaking changes; additive change: you don’t care if your delivery truck bringing your parcel also has other parcels on it.
Coordination with partners (e.g. WG/HBs/DHCW)
We must work across region, across Wales and across UK
Our collaborative efforts must be prioritised and supported
Some of what we need can and should be delivered by our partners
Investment in our data fabric
Raise the visibility of our data infrastructure
Balance short-term delivery goals with longer-term standardisation, harmonisation and documentation
Avoiding technical debt and ‘big ball of mud’ architectures; Infrastructure on demand and as infrastructure as code. Declarative.
Focus on interoperability, principled approach based on re-use, understand commonalities/foundational data structures
Re-usable tools
Investment in tooling, and pipelines, that are ‘invisible’ and yet vital. “Our plumbing”
Investment in our ability to extract, transform and load data; “internal interoperability”
Could and should be shared across Wales
Open standards, and open-source at foundations
Education and training
Health and social care
Regional partnerships
Inculcate art-of-the-possible, data skills, across organisations
Workshops, investment in training, workforce and digital skills, peer support
There are common themes across these requirements mainly in relation to prioritising, investing in, collaborating and governing
in relation to data.
I’d be interested in your feedback. What else have I missed? What should be in the data strategy for
Cardiff and Vale University Health Board, or for any healthcare organisation for that matter?
]]>NHS number validation and synthetic generation2023-09-29T17:16:16+01:002023-09-29T17:16:16+01:00https://www.wardle.org/open-source/2023/09/29/nhs-numberI’m pleased to announce the release of nhs-number.
This is a very small open source library available for both server-side and client-side
use. It is written in Clojure/Script and so can be used, for example, on the JVM (servers)
from Java or Clojure, or transpiled to JavaScript to be used in web browsers (clients).
In many domains, software developers make use of a range of foundational data and software
services. They don’t need to re-invent the wheel; they’re focusing on getting to where they
need to go.
Things are so very different in healthcare.
Not only do you have to overcome fundamental problems with the commercial market failure for
health and care software, byzantine procurement rules, as well as considering your information
governance and regulatory compliance obligations, you have very few libraries and frameworks
on which you can build your point of differentiation.
Of course, we have access to general purpose libraries, such as supporting secure networking
or encryption, or data storage. When we write software, whether for the web, or for iOS, or
Android, or Windows, we think about making use of a general purpose computing platform. It
is rare for us to build software without foundational core tools and services. Sometimes
those platforms are open-source, and sometimes those are proprietary, but they are available
and re-usable and composable so you can focus on the problems you are trying to solve.
But there is a dearth of high quality, well tested and functional libraries in health and care.
nhs-number is a small library that:
is published under a permissive open-source library you can view and modify the source code
has extensive tests, in including the use of synthetic (generative) tests
has an automated continuous test/integration/deployment pipeline so that any modifications result in updated
tests and automated reports - e.g., see this report
I already use it server-side for validation of data consumed from other services, and client-side to check user input is valid.
I also use it to generate synthetic data for automated tests in other systems.
If a patient has a type of motor neurone disease, then…
If a patient takes an ACE inhibitor, then …
If a patient has a type of autoimmune disease, then …
Whether we are writing software to build compelling user-facing applications, building rules or decision support,
or choosing categories from which we will run analyses such as understanding patient outcomes, we need to be able
to process health and care data and make inferences.
My open source software codelists generates versioned codelists
for reproducible data pipelines and research.
In general, there are two ways to think about codelists and reproducibility.
The first is a explicit human curation of a list of codes. This is the approach adopted by
Ben Goldacre and the opencodelists team. You create and share codelists.
The second is to define a codelist using a declarative specification which can be
used to dynamically - but reproducibly - generate the codelist.
At the time of writing, this manually curated list includes one active concept and
two inactive concepts.
276401000000108 Fast track referral for suspected colorectal cancer
276411000000105 Urgent cancer referral - colorectal
276421000000104 Urgent cancer referral - colorectal
While this is a useful set of curated terms, I would argue that it is better to simply
define this codelist using a SNOMED CT constraint using the syntax of the SNOMED CT
expression constraint language:
Based on a named versioned distribution of SNOMED, and defined versions of this
tool, this specification can be used to generate a reproducible codelist. If SNOMED CT
changes over time, this specification will continue to work, due to the semantic
relationships within SNOMED CT. codelists can expand a set of codes to include
now inactive concepts using historical associations.
Certainly for drugs, a declarative rules approach works better than the manually
curated set of opencodelists. If new drugs of a type are added to the UK dictionary
of medicines and devices (dm+d), then codelists will include those new drugs
without any manual intervention, while manual curation requires continued
monitoring and maintenance of code lists.
How to use codelists
You can define codelists using a variety of means, such as
ICD-10 codes for diagnoses
ATC codes for drugs
SNOMED CT expressions in the expression constraint language (ECL).
You can combine these approaches for high sensitivity, or manually derive codelists using hand-crafted ECL for high
specificity.
codelists is a simple wrapper around two other services - hermes
and dmd. I think it is a nice example of composing discrete, but related services
together to give more advanced functionality.
codelists operates:
as a library and so can be embedded within another software package running on the java virtual machine (JVM), written
in, for example java or clojure.
as a microservice and so can be used as an API by other software written in any language
The substrate for all codelists is SNOMED CT. That coding system is an ontology and terminology, and not simply a
classification. That means we can use the relationships within SNOMED CT to derive more complete codelists.
If you only use the SNOMED CT ECL to define your codelists, then simply use hermes directly.
You only need the additional functionality provided by codelists if you are building codelists
from a combination of SNOMED CT ECL, ATC codes and ICD-10.
ATC maps are not provided as part of SNOMED CT, but are provided by the UK
dm+d. ICD-10 maps are provided as part of SNOMED CT.
Using codelists
You can realise a codelist, expanding it to all of its codes. You can also test membership of a given code against a
codelist.
All codelists, by default, expand to include historic codes. This will become
configurable, but is the default for greater sensitivity at the expense of specificity.
Different trade-offs might apply to your specific project.
Boolean logic is supported, with arbitrary nesting of your codes using a simple DSL.
A codelist is defined as names and values in a map, with the names representing the codesystem
and the values the specification.
{"ecl":"<<24700007"}
This defines a codelist using the SNOMED expression constraint language (ECL). While ECL v2.0 supports the use of
historic associations within constraints, I usually recommend ignoring that ‘feature’ and instead defining whether and
how historic associations are included as part of the API.
SNOMED CT, in the UK, includes the UK drug extension with a 1:1 map between SNOMED identifiers and drugs in the official
UK drug index - dm+d
(dictionary of medicines and devices). That means you can use a SNOMED expression to choose drugs:
{"ecl":"(<<24056811000001108|Dimethyl fumarate|) OR (<<12086301000001102|Tecfidera|) OR (<10363601000001109|UK Product| :10362801000001104|Has specific active ingredient| =<<724035008|Dimethyl fumarate|)"}
Note how SNOMED ECL includes simple boolean logic.
But `codelists’ supports other namespaced codesystems. For example:
{"atc":"L04AX07"}
Will expand to a list of SNOMED identifiers that are mapped to the exact match ATC code L04AX07 and its descendents
within the
SNOMED hierarchy.
A SNOMED CT expression in the expression constraint language must be a valid expression.
ICD-10 and ATC codes can be specified as an exact match (e.g. “G35”) or as a prefix (e.g. “G3*”). The latter will
match against all codes that begin with “G3”.
Different codesystems can be combined using boolean operators and prefix notation:
{"or":[{"atc":"L04AX07"},{"atc":"L04AX08"},{"ecl":"(<10363601000001109|UK Product| :10362801000001104|Has specific active ingredient| =<<724035008|Dimethyl fumarate|)"}]}
This expands the ATC codes L04AX07 L04AX08 and supplements with any other product containing DMF as its active
ingredient.
If multiple expressions are used, the default is to perform a logical OR. That means this is equivalent to the above
expression:
[{"atc":"L04AX07"},{"atc":"L04AX08"},{"ecl":"(<10363601000001109|UK Product| :10362801000001104|Has specific active ingredient| =<<724035008|Dimethyl fumarate|)"}]
Duplicate keys are not supported, but multiple expressions using different keys are.
{"atc":"L04AX07","ecl":"(<10363601000001109|UK Product| :10362801000001104|Has specific active ingredient| =<<724035008|Dimethyl fumarate|)"}
When no operator is explicitly provided, a logical ‘OR’ will be performed.
For concision, all keys can take an array (vector), which will be equivalent to using “or” using the same codesystem.
{"atc":["L04AX07","L04AX08"]}
Boolean operators “and”, “or” and “not” can be nested arbitrarily for complex expressions.
codelists also supports ICD-10.
{"icd10":"G35*"}
will expand to include all terms that map to an ICD-10 code with the prefix “G35”, and its descendents.
The operator “not” must be defined within another term, or set of nested terms. The result will be the realisation of
the first term, or set of nested terms, MINUS the realisation of the second term, or set of nested terms.
[{"id":374049007,"term":"Nisoldipine 20mg tablet"},{"id":13764411000001106,"term":"Amlodipine 5mg tablets (Apotex UK Ltd)"},{"id":376841009,"term":"Diltiazem malate 120 mg oral tablet"},{"id":11160711000001108,"term":"Exforge 10mg/160mg tablets (Novartis Pharmaceuticals UK Ltd)"},{"id":893111000001107,"term":"Tildiem LA 300 capsules (Sanofi)"},...
For reproducible research, codelists will include information about how the codelist was generated, including the
releases of SNOMED CT, dm+d and the different software versions. It should then be possible to reproduce the content of
any codelist. At the moment, only the data versions are returned:
Clojure is a programming language that is a dialect of Lisp, but none of the concepts here require the use of Clojure as
a programming language. Rather, this talk is more about learning from some of
the principles behind Clojure, and functional programming languages generally,
and internet-era software architectural design, to re-imagine the software we use in health and care.
Introduction
In this blog post, I argue that we must transform the way we perceive and use electronic health records (EHRs).
By employing the principles of Clojure and reimagining the EHR, we have the potential to turn this essential tool inside
out, unlocking its full potential, and support a health and care system designed around the needs of patients and
professionals.
Traditional EHR vs inside-out thinking
To begin, let’s understand the traditional or conventional Electronic Health Record (EHR). Typically, an EHR is
considered an application or system that healthcare providers purchase, deploy, and often integrate with other systems.
These EHRs are organization-centric, designed to meet the needs of the purchasing entity, and are heavily focused on
process and billing. They tend to be monolithic, with proprietary internals and limited interoperability within the
product. Interoperability is considered ‘external’.
In essence, EHRs are like isolated islands in the digital healthcare landscape, making integration complex and resulting
in data concretions within an enterprise. Patient data is contained within these applications, making it challenging to
use the same data for different purposes like population health analytics, service management, and research.
Furthermore, the tooling used for EHRs differs significantly from what is required for analytics and research.
For example, we may use Python or R for research, proprietary tools for analytics in managing services,
and very different tools for applications supporting direct care.
Unbundling the EHR
The concept of unbundling the EHR involves shifting the focus from the organization to the patient and adopting the FAIR
principles: findability, accessibility, interoperability, and reusability. In this model, data becomes the central
element, with the potential for easy composition of data from multiple organizations, regardless of their origin. This
shift allows us to move beyond process measures to more meaningful outcomes in healthcare.
By concentrating on data, the architecture inherently becomes distributed, similar to how we build external systems.
This approach is inspired by Rich Hickey’s concept of using plain data, RPC, and queues in system architecture. The
result is a suite of independent but composable computing and data services, both internally and externally
interoperable. These services provide flexibility, adaptability, and scalability, aligning with the dynamic nature of
healthcare.
We must move to a domain-driven design in health care.
Interoperability
In healthcare, interoperability has been a long-standing challenge. Various approaches, such as convergence through
shared applications or information exchanges, have been attempted. However, these approaches often fall short,
especially in supporting granular analytics and research.
A more effective solution is to approach interoperability through composition and layering of domain-aligned data and
software components. Instead of forcing organizations to adopt a single shared application, the focus shifts to
standardized data exchange. This enables the creation of shared care records that may not contain all the detail but are
sufficient for many purposes.
Domain-Centric Approach
Breaking down the EHR into its domain-specific components can provide clarity and facilitate meaningful, semantic
interoperability. Components related to radiology, staff, patients, reference data, classifications, and terminology
can be understood and managed individually across organisational boundaries. It is seductive to think that a single
system can do all that we need, but health and care is too complex and needs to be broken up into smaller, manageable
chunks which can be developed and improved independently.
An approach predicated upon organisations and not health and care domains creates fragmentation and loss of shared
semantics. Traditional EHRs often adopt the shared single instance approach or attempt to converge various systems.
However, this
can lead to fragmentation and a lack of shared semantics. Unbundling the EHR, on the other hand, enables data to flow
seamlessly and allows for dynamic composition of services, resulting in a more cohesive and flexible healthcare
ecosystem.
For example, an organisation-focus means that a staff member who works across multiple sites may need multiple logins
and find it difficult to generate a report detailing all of the surgical procedures performed across those sites, as
there may not be shared understanding of the identifiers that underpin that staff member. If they are a prescriber, each
organisation must be careful to register their accounts so that they have access to e-prescribing.
Instead, we should be recognising the importance of domain-boundaries, and that a staff index, and associated data
such as scope of practice, and regulatory informaion, is a first-class, important domain within health and care; likely
needing federation and aggregation of a number of disparate sources of information, but presented as a unified, and
simpler service to other domain components.
Turning electronic health and care records inside-out
What can we learn from Clojure?
While Clojure is an excellent language to implement the software for the next
generation of electronic health record systems, we can learn the most from the principles
that underpin the design of Clojure:
Data-orientated
First class names
Working to abstractions
Functional / pure functions / reproducibility
Immutability
Loose coupling
Dynamic / flexible / adaptive to change
First class events / event modelling
Building the internals of our systems as in the large (Internet-era approach)
Using these principles, we can look towards interoperability through composition and layering
of domain-orientated data and software components.
Example : thinking about analytics for electronic prescribing
Imagine a scenario: You’re in a hospital, and you need to closely monitor all the antibiotics being prescribed to
patients. It’s a critical task that can impact patient outcomes, but it’s also one that can be quite complex due to the
diverse nature of healthcare systems.
Option 1: Leveraging In-Built Analytics
The first option is to rely on the built-in analytics tools provided by EPMA (electronic prescribing and medicines
administration)
or Electronic Patient Records (EPR) vendors. These tools are designed to work seamlessly within their respective
systems, offering insights
and analytics specific to that environment. While this option can be effective within the confines of a single system,
it falls short when dealing with the intricate web of healthcare data spread across different platforms.
In the real world, many hospitals use different prescribing systems, each tailored to a specific aspect of patient care.
For instance, chemotherapy prescribing systems differ significantly from those used for general medical purposes.
Moreover, various healthcare enterprises, including community services and general practitioner surgeries, operate on
different systems altogether. This fragmentation poses a significant challenge when aiming for a comprehensive,
population-level analysis of healthcare data.
Option 2: Embracing Health Information Exchanges
The second approach involves aggregating data from various sources into a Health Information
Exchange (HIE). An HIE acts as a bridge between disparate healthcare systems, allowing data to flow between them. While
this approach can provide a degree of standardization and interoperability, it doesn’t fully address the underlying
issues of data granularity and accessibility. In essence, it’s a step in the right direction but may not be the ultimate
solution for comprehensive healthcare data analysis.
Option 3: Unbundling Electronic Health Records (EHRs)
Now, here’s where unbundling the Electronic Patient Record (EPR) or Electronic Health Record (EHR) system comes in.
In simple terms, this means taking the data generated by these systems, transforming it into a standardized,
self-describing event stream, and making it accessible for a wide range of applications, including direct-care (e.g.
alerts),
analytics (a dashboard of all antimicrobials across an estate), and research.
This unbundling process begins with extracting data from these systems. While many suppliers can provide data feeds in a
standardized format, some may require transformation and extraction to create a consistent event stream. Once achieved,
this event stream becomes a valuable resource for healthcare professionals.
The Power of Data Annotation
To maximize the utility of this event stream, we must recognise the importance of data annotation. This involves
enriching the data with additional information using terminology and drug dictionaries. For instance, a healthcare
provider can perform lookups against drug codes in the event stream, providing meaningful insights about the medications
prescribed. We must recognise that mapping and annotations are first-class problems in our domain, and those tools
should be available on demand, for a range of use-cases, and independent from individual vendors.
These annotated event streams can then be divided into substreams, each tailored to specific aspects of patient care.
For example, an antimicrobial event stream can be created and used to populate a real-time dashboard, enabling
healthcare providers to monitor antibiotic usage and make informed decisions promptly.
Transforming Healthcare Data Management
In essence, the vision revolves around turning the traditional approach to EHRs inside out. Instead of
relying solely on monolithic EHR systems, healthcare institutions should be able to embrace the power of first-class, composable data
and software services. This shift would allow for dynamic data composition and interoperability spanning organizational
boundaries, ultimately benefiting patient care, analytics, and research.
As healthcare continues to evolve, the ability to harness and analyze data effectively becomes paramount. By breaking
down data silos, enhancing interoperability, and making data truly first-class, the healthcare industry can take
significant strides
toward improved patient outcomes and a more efficient healthcare system. It’s a journey that requires effort and
collaboration and a foundation of vendor-neutral, and open, data and computing services.
First-class annotation and mapping
In the world of healthcare and patient care, one of the most crucial aspects is the ability to make sense of the vast
and ever-evolving landscape of health and care data. This requires the use of standardized terminologies, and one example
is SNOMED CT. Driven by the need for dynamic and adaptable software systems, we need ubiquitous tooling that harnesses
the potential of SNOMED CT in healthcare, providing access to its power in any application, for any purpose.
For example, we can standardise on vocabularies, such as the list of specialty codes. However, such an approach leads
to concretions in our software systems, because if the master list of codes is updated, any software that needs to make
sense of those codes needs to be updated. In addition, these codes are usually not self-describing, or contain
information about the relationships between those codes.
Instead, an ontology provides rich semantics supporting inference and sense-making.
For example, imagine I wish to build a compelling user experience so that a user can rapidly search for correspondence
relating to a speciality. If I have a flat list of codes, ‘neurology’ and ‘paediatric neurology’ are considered
independent specialties, and if I wish to allow users to search for ‘paediatrics’ and also include ‘paediatric neurology’
then I must build those kinds of rules outside of my vocabulary / classification list.
A more dynamic and flexible approach such as that enabled by SNOMED CT might allow a user to choose ‘neurology’ and find
letters for all types and subtypes of ‘neurology’ as a specialty, which would, of course, include ‘paediatric neurology’
by virtue of the ontological basis underpinning SNOMED CT. While some might think that this a dry and academic subject,
by getting our foundations right, we make it easier to build compelling, and delightful user experiences.
I’ve open-sourced a number of libraries and services that can support this kind of work:
This work should be open-source and available widely, and used for many different purposes, including direct care,
analytics pipelines and research. Such libraries and tools need to be quick to set-up and use, and not require
significant investments in infrastructure or server capacity. It makes little sense to not share foundational software
services. It is otherwise akin to developers needing to start by building their own encryption libraries; no-one should do that
but instead use open, readily available and battle-tested ready-made libraries.
Mapping and projections are first-class problems in our domain
We need to recognise, and therefore provide compelling, battle-tested solutions to first-class problems in our domain.
Recognising the issues forces use to focus our limited resources on things that have the greatest benefit. If we think
that building user interfaces is the biggest issue, then we spend our time (erroneously) building solutions for e-forms.
Instead, if we recognise the true (shared) challenges, then we should quickly see that semantic interoperability depends
fundamentally on data and software that can make sense of, and map between different ways of encoding health and care
data.
Here we see that, for a specific research project, I’ve taken complex, real-life hierarchical and nested health data and
generated a simplifed rectangular projection to make it easier for subsequent analysis. Fundamentally, the projections
will vary depending on context and use-case, so we must focus on capturing highly granular and specific data at the point
of care, while building tools and chains and data pipelines that permit turning that specific data into a variety of
formats convenient for the use-case at hand. Importantly, we delay the loss of granular information until as late a
stage as possible. Too many times, we look to ask professionals to record categorical data in order to simplify subsequent use of
those data, rather than capturing data at the right level of granularity for clinical use, and making use of the right tools,
and right expertise, to classify those data later on according to the need at hand. We should derive those projections.
Here is an overview of some of the tools I have built so far, in my spare time.
My current focus has been on lower-level, fundamental software and data services. However the future should be that we
build an ecosystem of composable higher-value components, well-tested and built by community efforts, relating to design
systems and decision support. Why are we building prescribing rules in proprietary software systems when the community
could be building in the open to be used for whatever purpose necessary?
Finally, I’ve recognised that one way of composing together data and software services within health and care is through
the use of graph APIs. Such APIs allow one to seamlessly navigate across disparate data services permitting user-facing
applications to be built independently of the the underlying software and data subsystems resolving the queries at hand.
In the video, I give a demonstration of using Hermes from a Clojure REPL, permitting interactive programming. For example,
I show how I can build a data pipeline that takes diagnostic and problem codes and map them into a specific emergency reference
set (subset) to simplify analysis.
Conclusion
In conclusion, the concept of unbundling the EHR and adopting Clojure-derived principles has the potential to
transform healthcare data management. By focusing on data, achieving interoperability, and leveraging standardized
terminologies, we can create a more flexible, adaptable, and patient-centric healthcare ecosystem. This approach not
only benefits direct patient care but also empowers analytics and research, ultimately leading to better outcomes in the
healthcare industry.
]]>Mapping the electronic health record 2/22021-12-14T14:14:14+00:002021-12-14T14:14:14+00:00https://www.wardle.org/strategy/2021/12/14/mapping-the-epr-2This is part 2/2 of my presentation at MapCamp 2021.
You can watch a video recording of that presentation if you like, but
this post is a
deeper dive into some of the detail.
2. Algorithms
So what about algorithms, and machine learning in health and care? Are you sure machines need anything different to what
we as humans need?
There’s a complete blog post about it, if you want
more detail.
But, you’ll see that whether you are looking to support a new clinical score that calculates stroke risk, or a new
machine learning algorithm that can interpret chest x-rays, computers need the same types of information and support and
feedback loops and monitoring as do professionals and services and facilities.
Our Wardley map shows dependencies on:
meaningful data
feedback looks
monitoring and evaluation pipelines
consent and control
readily available tools and libraries
What do we currently have?
This map looks at the electronic health record from the viewpoint of an organisation, because that’s the usual model of
how software used in health and care, whether for acute hospitals or community services.
In this map, I show a dependency from the organisation to an electronic patient record.
NB: I think that dependency and mapping from organisation to health record can and should be challenged. A patient
shouldn’t have to know that one specialist service is managed by that organisation and another from another; aren’t they
interacting with a health service that should feel seamless? They should not need to know organisational or department
structures. We need to move to a single logical patient record, even if that record is aggregated or federated from
multiple providers.
Many organisations have bought off-the-shelf electronic health record products. As part of that, they might also buy,
usually but not always from the same supplier, the following products:
a patient portal - to allow patients to interact with, or at least view their record, at that organisation
population analytics - to allow analytics across groups of patients
health information exchange - to share data between organisations in, for example, a region
an API product - to allow developers to build products using the data and services within the EPR.
An API is an “application programming interface” - in essence a way for systems or subsystems or modules of software to
communicate.
You’ll see from the map that the API product is usually dependent on the EHR in this model. We’re going to need to
challenge that, because health and care records should surely be built using open APIs, not the other way around?
How can it be that our APIs our dependent on the EPR, rather than our EPR being dependent on our APIs?
In addition, the organization wants to share data across a region so they buy the product’s linked health information
exchange (HIE) product. This means that they can exchange data with other hospitals and other organizations within that
region.
But far from reducing the need for in-house development capacity, the need for integration and customisation means many
organisations embarking on their EPR journey end up increasing the numbers of in-house developers. The EPR, costing
rather a lot of money, hasn’t really solved all of our problems at all, and what we think of as research remains
entirely separate. It is akin to thinking we’ve bought an ‘off-the-shelf’ suit, but actually needing to do a significant
amount of tailoring ourselves.
Importantly, spending this money on an EPR does not prevent us having to do some real work on proper collaboration and
cooperation across health and care whether it be for direct patient care, service management, improvement, monitoring or
research, for otherwise we still end up with data silos in which we cannot easily pool data. Indeed, we surely need to
prioritise that work rather than thinking we can defer until after our EPR deployment?
Dependencies, and tell me again why are we building our own data centres?
Our map also shows us that our in-house development, our EPR, our analytics platform, our health information exchange,
and patient portal(s) need infrastructure on which to run such as ‘compute’ and ‘data’ services. However, the map shows
that health systems still have significant legacy services that are bespoke and proprietary and custom-built, instead of
recognising that, particularly with limited local resource, we should be focusing on the things only the public sector
can do, and using off-the-shelf infrastructure on demand.
The big technology companies have so far pretty much failed in healthcare. I give them a D- “Could do better”.
They’re fixated on infrastructure, particularly cloud services. Apple is an exception with its Apple Health app serving
as a patient portal.
The fundamental question for electronic health records (EHRs) is whether to buy from one vendor or assemble a
best-of-breed system, both of which can lead to complexity, particularly if we use point-to-point integration patterns
rather than a common shared platform. Buying the components from a single vendor, or integrating best-of-breed can result
in a fossilised architecture which is difficult to change, proving to be inflexible and difficult to adapt to changing
requirements. There can be a combinatorial explosion unless we build a platform on which disparate applications and
services can sit.
Finally, we should also ask why are healthcare data for analysis, research and direct care kept separate? They should be
integrated for better patient care, with the same data used for multiple purposes. For example, direct patient care can
surely be aided by real-time analytics - I’ve previously shown examples where my own EPR has plotted disease outcomes over
time for a single patient compared to an aggregated dataset of similar patients to aid shared decision making and understanding.
Many of our issues in health and care are cultural and historically. Why do we use different programming languages
and data stores for analytics and EHRs and therefore hindering progress. We need to challenge these assumptions while embracing
standardization and mapping of data. Why are we standardising applications that are difficult to integrate, rather than
standardising our data?
What do we need?
For EHRs, you can choose a monolithic system like Epic or Cerner, which handle billing, clinical data, identity
services, and orders. Workflow support is lacking and clinical calculators are often proprietary. Data sharing is
challenging and should be standardized.
Decomposing the electronic health record
Here’s what happens when we buy a monolith:
It still will need to be integrated to a PAS, to radiology and likely a separate laboratory
management system. It may even not be a monolith itself - for example, Cerner’s EPR is
actually a combination of a number of different products made to look like a single application.
Alternatively, a best-of-breed approach allows you to integrate various systems, but it’s complex and custom and
potentially difficult to flex and adapt in the future.
Instead of focusing on the needs of an EHR, we should prioritize user needs, including researchers, clinicians, and
patients. Decision-making relies on evidence, communication, and action. We lack sophisticated decision support tools
and meaningful data, often siloed within organizations.
To improve healthcare, we need to share data securely, enhance trust, and implement open standards. Workflow management
and process orchestration are vital. Users should control their data with advanced technologies like secure enclaves and
homomorphic encryption.
Foundational services should be open and standardized, focusing on clinical data, reference data, and commodity compute
providers.
In the future, we should aim for user-centered applications, trust, and outcomes. Transparency, collaboration, and
openness are key principles. Open source should drive the adoption of open standards.
Modern technology companies should view the cloud as more than a data center relocation, leveraging its potential for
healthcare. This shift can disrupt the existing market, emphasizing value and patient outcomes.
Thank you.
]]>Mapping the electronic health record 1/22021-10-21T08:00:00+01:002021-10-21T08:00:00+01:00https://www.wardle.org/strategy/2021/10/21/mapping-the-epr-1This blog post is based on my presentation at MapCamp 2021.
You can watch a video recording of that presentation if you like, but this post is a
deeper dive into some of the detail.
There are many parallels between clinical decision making and strategy.
We need information at the right time for our decision making, with feedback loops, whether for direct care, management of services or reproducible research.
Health and care should be data-driven.
Health and care should be based upon openness, transparency, collaboration and continuity, with meaningful data.
Trying to fix health information technology through the prism of an organisation-centric electronic health record is difficult and we need to step back and re-appraise.
Understanding the needs of the EHR (electronic health record) is useful in understanding how to deconstruct the EHR.
Modern technology companies have generally failed in health and care so far. They now focus on generic data and computing services but cloud technology should be more than simply moving a data centre to someone else’s kit.
We should be building the tools to build EHRs, not another EHR.
The foundational software and services and tools to build EHRs should be commodities, open-source and widely available leaving the market concentrate on higher-value differentiation to support decision-making. Such services can and should be provided as shared, highly resilient, managed services.
A learning health and care system must be flexible and adaptable, so the priority should be in providing configurable composable tools to manage workflow and orchestration of processes across organisational boundaries.
What is Wardley mapping?
An excellent way to understand our current state is to start with user needs. We need situational awareness.
Wardley mapping draws a chain of user needs from top to bottom, demonstrating the required capabilities on a chart that moves from left-to-right in which things on the left are poorly understood and in evolution and things on the right are evolved and commodities.
As a result, you will find potentially high-value but perhaps poorly understood, poorly systematised elements on the left of the chart.
Over time, these elements are likely to move rightwards and become more accepted. As such, the map helps you realise, or at least prompt debate, on where to invest your time and effort.
In addition, you might find elements of your organisation, or your ecosystem, seem to be in the wrong place. For example, you might be building your own data centre and your organisation is treating it as leading edge; as you draw your map you realise that is wrong.
Maps facilitate shared discussion.
All my maps are wrong but I hope they might be useful!
Let’s start!
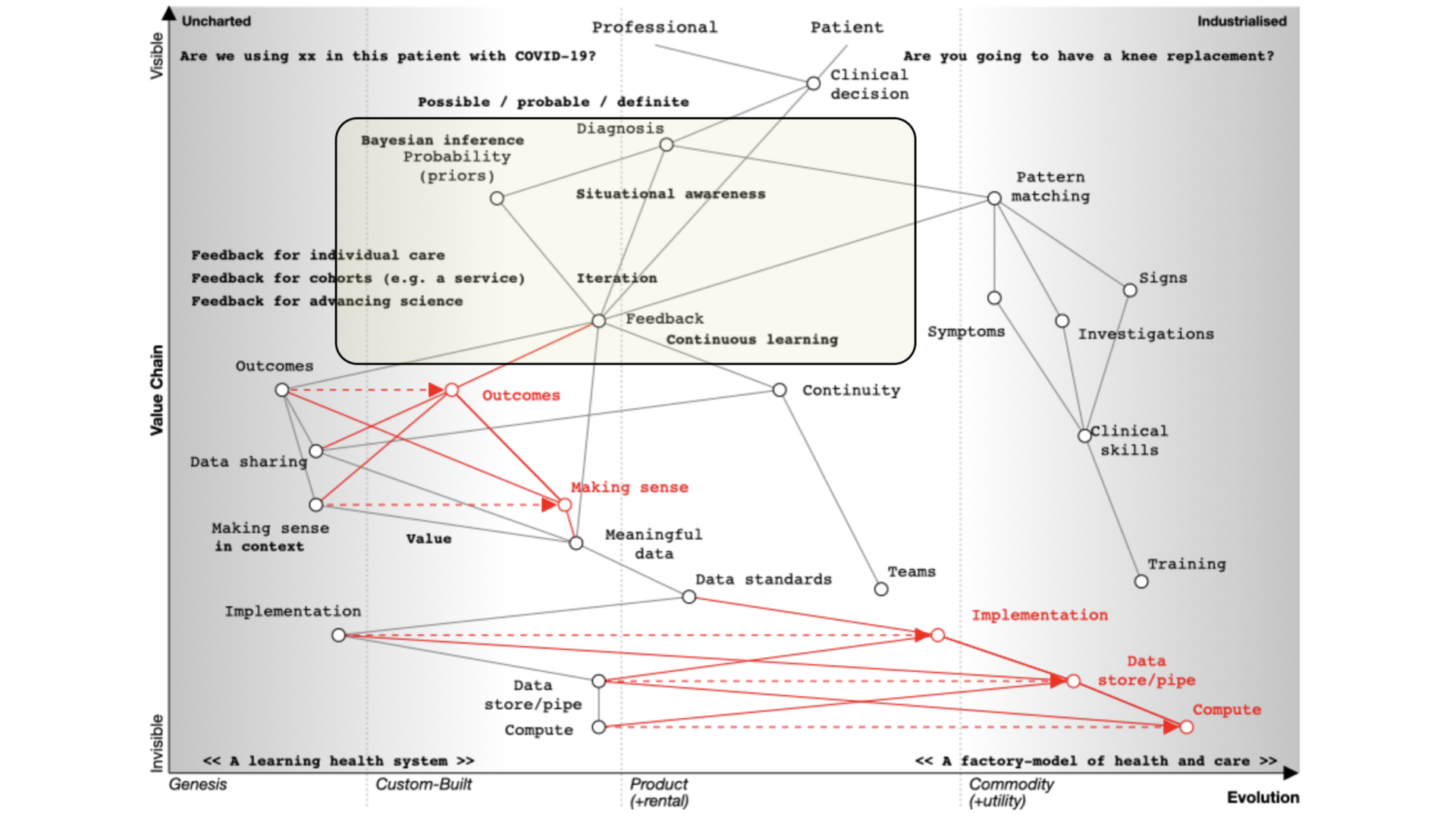
1. Clinical decision making
I would like to discuss diagnosis, management and decision making and the use of data in supporting the health of a nation.
There are parallels between clinical decision making and strategy.
Our default must be that we’re always orientated towards action - so that means making decisions.
If I’m seeing you in my clinic, we need to make a diagnosis and a management plan together - we need to ask ourselves what are we going to do; it requires *information at the right time. We might take action and measure the response and change our course.
Most of what we have in health information technology is unintentionally designed and it’s evolved organically and it’s not fit for purpose.
If you’ve not used Wardley mapping before, this map may look complex. But it isn’t. We simply need to read it from top to bottom. I’ll explain this in more detail below.
We start with a situation of uncertainty. We benefit if we reduce the uncertainty around a specific decision so that we can make better decisions.
At the top of the map, we have a professional and a patient and we’re making a decision.
Are you going to have that knee replacement?
What are the trade-offs here?
What are the pros, what are the cons?
Are we going to use this new treatment with this patient with COVID-19?
How do we identify the patient with COVID-19 who’s going to need higher level care?
Whatever the decision, it is dependent on our diagnosis of the problem. I’ve annotated ‘diagnosis’ on the map as ‘possible’, ‘probable’ or ‘definite’ so already we’re starting to think we are creating something that is iterative.
We’re going to need feedback loops because we may need to make a speculative diagnosis and confirm and adapt as we go. We do not have a linear process but instead we use results to not only confirm but refute our thinking. Feedback loops support the ‘clinical method’ in which we combine information about diseases with information about the patient and our context.
We need to understand that a priori probabilities - we use Bayesian inference based on the prior probability of that diagnosis.
That means that if a patient has a fever and we are in Africa it’s likely to be a different diagnosis than if one has a fever in the United Kingdom. Context matters.
We also work on pattern matching:
That’s what we teach at medical school and it’s well developed and well evolved. We teach it we expect it to be done propertly and consistently. We look at symptoms, what the patient describes; signs, the things that we can find on examination and we use investigations and all are dependent on training that occurs over many years. It should be no surprise that the patterm-matching pathway is over on the right of our map.
Learning through doing - feedback
We learn through a process of ‘doing’ which makes feedback essential. As a result, in the map you can see an iterative loop where we’re continuously learning.
You can imagine that type of feedback loop in three broad categories of iteration:
You’re caring for a single patient and arrange
tests or treatments and use the results and outcomes to modify the plan.
You’re looking at cohorts of people - e.g. those attending a service or facility, or somebody as defined by their characteristics such as ethnicity, age, problems, diagnoses, or the treatments that they’ve had.
You’re trying to advance science so it’s actually clinical research in which a group of patients is compared to another after, perhaps, randomisation, or simple observation.
Frequently, these three use-cases are treated very separately, which we’ll discuss later. Ask yourself why when they are fundamentally the same, but perhaps at different levels of acuity and consent. All need to be reproducible and replicable across different cohorts.
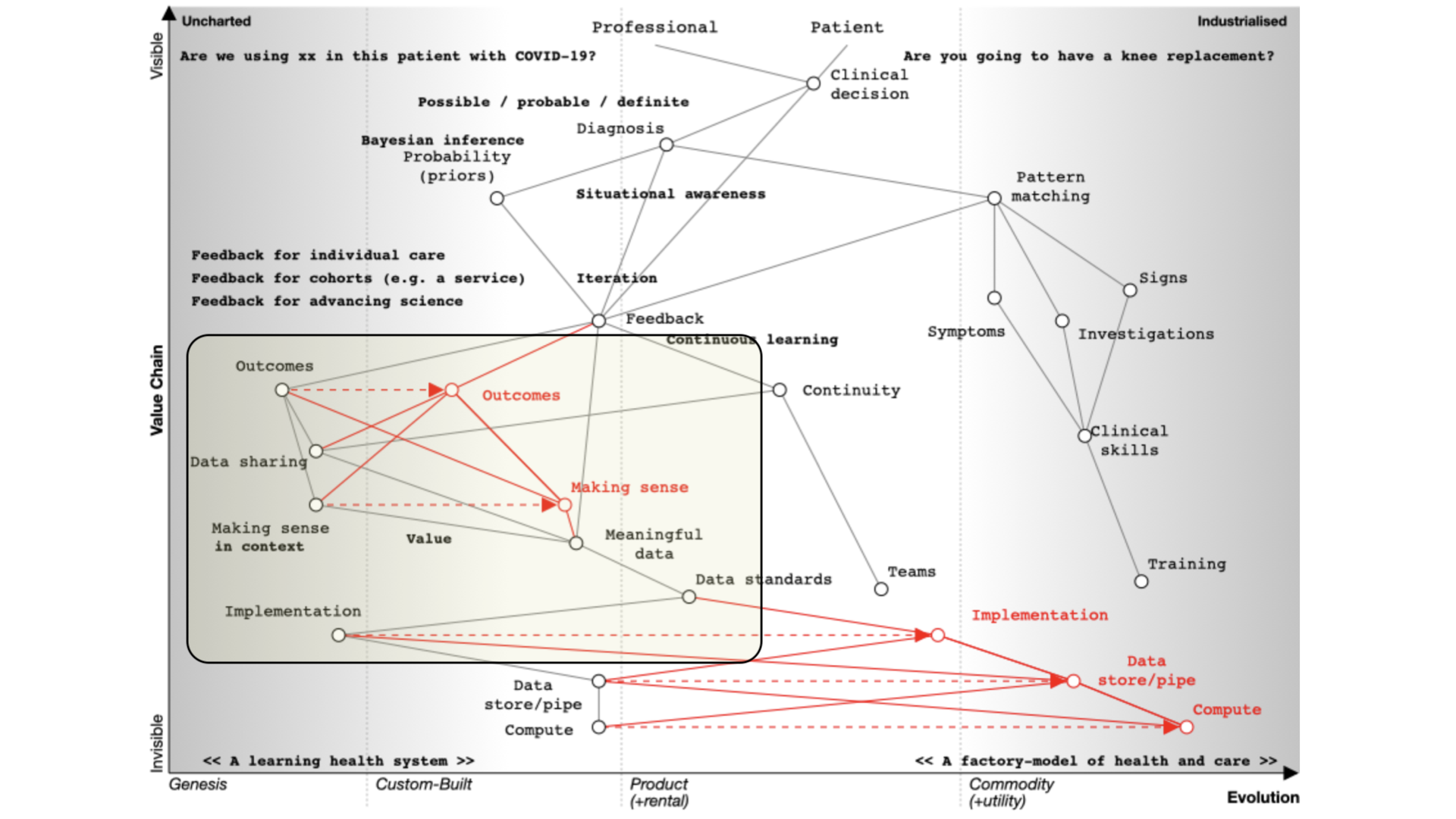
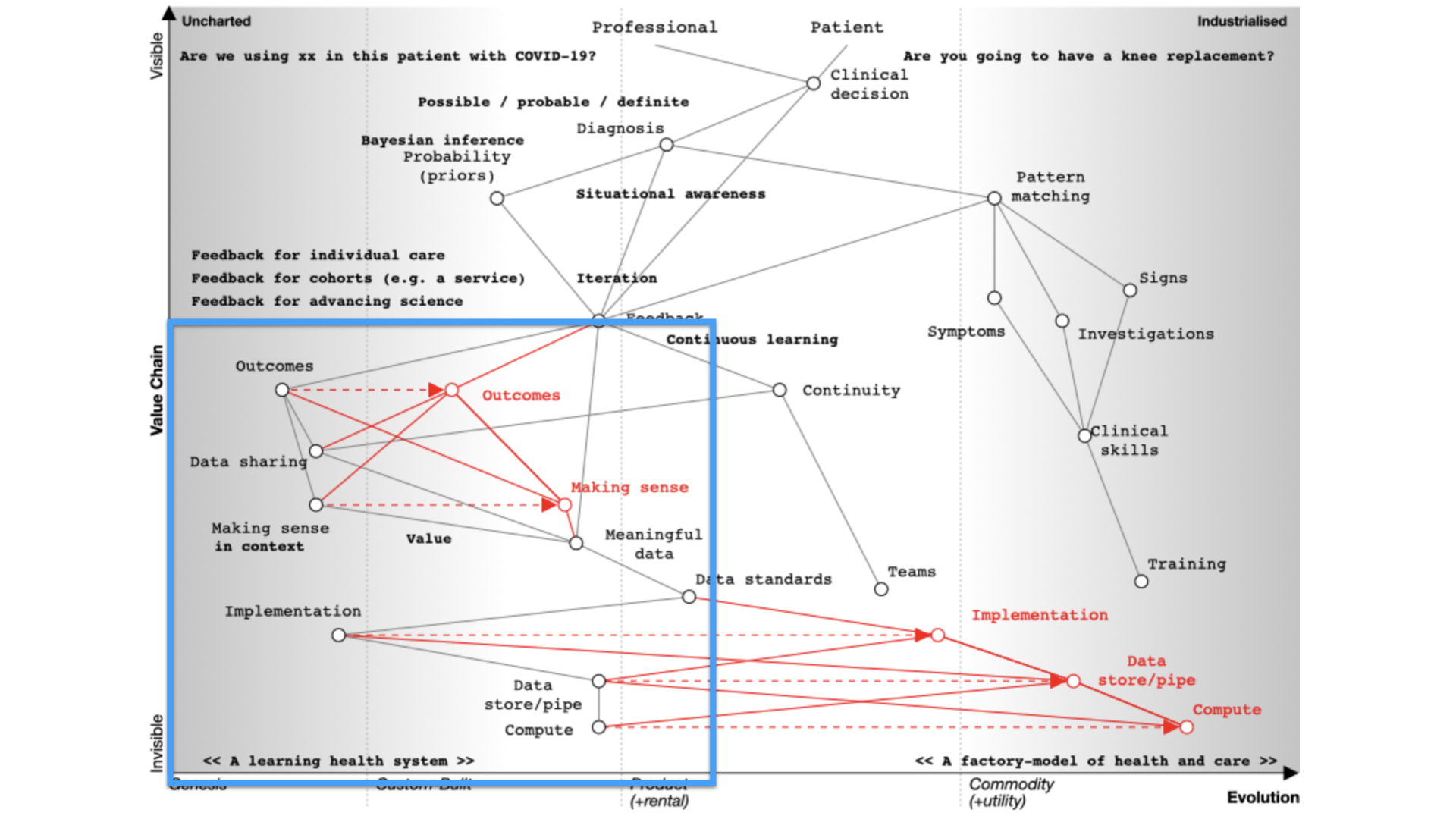
Supporting continuous learning
For continuous learning we need continuity and a focus on outcomes.
Paradoxically, many digital tools reduce continuity because they are used as part of reducing health and care to a system focused on transactions like a call-centre.
How do we assess what we’re doing unless we’re measuring outcomes in a systematic fashion?
If we need continuity and we want to focus on outcomes we need to routinely and systematically share data. Currently, it is not, except for specific examples such as registries.
Similarly, we’ve got to make sense of that data in context. If we’re going to measure outcomes, it’s no good just assuming that we can interpret those results - we need, as is plotted on the map, meaningful data and supporting data standards in order to aggregate, make sense and deduce.
For example, I’ve got work that shows how a patient with multiple sclerosis progresses over time but that only makes sense if you compare that patient to the rest of the cohort.
We need tools and data in order to support our decision making. That’s because we need to collect the same kind of structured data and inculcate semantic interoperability with widespread implementation of open standards.
Current implementation of standards is patchy. Many implementations are proprietary, and it is usually more difficult to use a standards-based approach than something custom-built that tightly couples components with end-to-end bespoke integration.
In many circumstances, health and care providers need to buy a product in order to implement a standard. That’s akin to you needing to buy encryption for your web browser.
It therefore follows that there is an opportunity to disrupt the status quo with readily available open-source implementations of data standards and making data standards and data interoperability commodity ubiquitous across our ecosystem. This is a cultural change that is gaining momentum.
So the maps help us identify the areas we might wish to focus our attention.
Are you a clinician about to see a patient, reviewing the patient record in order to prepare for the consultation?
Or are you a manager assessing the demands on your services, and running quality improvement projects in order to improve your outcomes?
Or perhaps you’re a researcher looking to extend knowledge and inform the best clinical practices of tomorrow?
Most of us working in health and care operate in all three of these domains, but historically, each is considered separate.
Patient records might still be on paper, or perhaps you use an electronic patient record system.
Your administrative data including time from referral to different assessments and treatments are held in a patient administrative system, or more likely, across multiple administrative systems, one or more for each organisation.
Your research might use a bespoke registry or research system for each of your research projects.
Software in health and care
Software is like magic offering us the potential to automate and systematise safe and effective clinical processes and most importantly, build learning systems that can continuously monitor and improve from where we are currently.
As a result, digital, and being data-driven, means our planning cycles should become shorter and shorter, because we’re using small focused interventions and data to constantly evaluate our hypotheses and build a continuously learning healthcare system.
We separate the things that should be the same.and we join the things that should be separate.
Here’s an example from the past. The Bristol Heart scandal occurred in Bristol, UK in the 1990s, in which babies died at high rates after cardiac surgery. The report into the scandal including this in its conclusion:
The various clinical systems, many of them paper based, differed from one another and had no relationship with the administrative hospital-wide systems. The funding made available in the late 1980s and early 1990s for medical and later clinical audit helped to reinforce this separation by making available to groups of clinicians money for small local computer systems. The lack of any connection between these different systems, one administrative, the others clinical, for collecting data cannot be explained solely on the basis of some technical or technological reason. It was just as strongly a reflection of a mindset that clinical matters were the sole domain of clinicians and non-clinical matters, to do with the management of resources and with the movement of patients into and through the hospital, were the preserve of managers and administrators.
But why do we separate clinical from administrative systems, and both of those from research systems?
There are a variety of reasons, including understanding who has responsibility for procuring, funding and designing such systems as well as issues of information governance.
The false separation of the needs of these three - administration, clinical practice and research, is so embedded in our culture that we even often use different tools, languages and frameworks to build the software - you might run R and python for your research, your analytics by an off-the-shelf package such as Qlik, and your electronic health record software in java or C++.
But are they so different really?
It’s straightforward to think of examples in which it is helpful to combine data relating to what is traditionally considered to be administrative with clinical data. One good example is the flow of patients through a hospital - lengths of stay are best understood in the context of medical problems and co-morbidities. Another might be making sense of clinical or diagnostic information, such as how many patients are referred with problem ‘x’. It’s all data, and it makes little sense that we use widely different software for the different purposes to which we put our data.
So what’s the solution?
A single system?
So why not have a single system? What a seductive yet naive idea!
Its naive because what do we know about building effective, adaptable, flexible computer software?
“Flow is difficult to achieve when each team depends on a complicated web of interactions with many other teams. For a fast flow of change to software systems, we need to remove hand-offs and align most teams to the main streams of change within the organization. However, many organizations experience huge problems with the responsibility boundaries assigned to teams. Typically, little thought is given to the viability of the boundaries for teams, resulting in a lack of ownership, disengagement, and a glacially slow rate of delivery.”
Skelton, Matthew. Team Topologies (Kindle Locations 2147-2151). IT Revolution Press. Kindle Edition.
We have to break up our complex health and care domain into smaller subunits. It’s just too complicated and its safer and more effective to break up our problems into smaller tractable problems.
Health professionals can be seduced by the idea of buying a ‘single system’ in order to solve their problems because, quite rightly, they’ve been scarred by their experiences having to use multiple ‘systems’ in order to get the information that they need - paper records, that system, another system, another login, a different login.
But, but but!
But there is a paradox. We know that the worst ways to create a seamless “one system” approach are thinking we can build a single monolithic application or expect the procurement of a “system” to solve, for example, closer working and communication between health and social care.
The best way to slow down delivery is to have an approach to technical architecture and wider governance structures that slows down the software value chain. The key to software delivery is delivery, and yet some organisations treat software as if they were managing capital projects such as building a new road or a bridge. In most cases, the technology is the easy bit; its the implementation on the ground across multiple complex adaptive systems that is most difficult. But we also need a design that makes it easy and safe to change.
People who think building technology is difficult and complex tend to want to centralise and control its development, because that feels less risky, but that approach is wrong.
If we believe that software can make our work in health and care more effective, are we using the right methods in order to safely deliver that software, at pace?
We know existing software systems, whether for direct patient care, for analytics / governance or for research, we seem to make the same mistakes again and again:
Too often, software architecture and system design occurs as a consequence of organisational or management structures, rather than stepping back and truly understanding the problem domain and how to carve it up into manageable chunks. You need to understand Conway’s Law, and the reverse Conway’s manoeuvre - and place the patient foremost in the design and architecture of your systems.
The dependencies between architecture, governance and standards, June 2021
The conclusion must be, therefore, that we need to step back and re-appraise how we architect, fund and standardise digital health and care.
We can get a ‘single system’ by focusing on data, standards, architecture and modularity, and enable innovation and continuous improvement - and not unduly limit our ability to adapt and change to the ever changing requirements the complex adaptive domains of health and care throw at us!
Towards data, data-driven health and composable modularity in software infrastructure.
Firstly, we’ve got to recognise that fundamentally, it’s all just data.
We need to collect, make sense of and use data in order to do what we want to do, whether that’s running our health services, seeing an individual patient, improving our services or furthering our medical knowledge.
Secondly, we need structured meaningful data and that means data standards.
If we think you have had a myocardial infarction, then we need computer systems that can make the same sense of the data, and we need to think of our different sources as reference data as products - and use ‘product-thinking’ in how we publish, document, and make those data available - it needs to consider user experience of that data product in just as much of a way as a user-facing application.
Thirdly, we need to make using data, and using data standards as easy as possible.
No-one starts building software nowadays from nothing, but instead make use of a range of standard building blocks in order to achieve the functionality they want - whether its a cryptography library, or machine learning, or networking, these elements are commodities - usually open-source, widely available and widely-tested.
So if you’re starting to build clinical applications now, where are the building blocks, the commodity libraries, frameworks and services with which you can innovate? Where is the platform on which you can build?
We need readily-available software modules that can make consuming and making sense of data as easy as possible. That means many software services that simply wrap reference data in order to make it usable in whatever context you need and that those services are composable with others much like an orchestra is made up of many different sections, instruments and musicians. And who can argue with Aristotle? “the whole is greater than the sum of its parts”.
What are the building blocks?
When I first built an electronic health record system, I needed the basics - understanding who the patient is, who the professional was, when someone was seen, where they were seen, what were the characteristics that help define the cohort - such as problem, diagnosis, treatment whether by surgery or drug, and geographical indicators, or derived indicators such as socio-economic deprivation.
I’ve realised that building such functionality into a single system is wrong.
As such, I’ve developed replacements as individual software components. Each is usable in isolation but I can combine them, whether as libraries in a single application or as a suite of individually running microservices, in order to solve problems. Each is designed for use in operational administrative, clinical and research systems - so are usable for direct care, service management or in my analytics. Each is open source.
hermes - a SNOMED CT terminology server and library.
dmd - UK dictionary of medicines and devices server and library
clods - UK organisational and geographical reference data, including a FHIR r4 server
deprivare - UK deprivation indices made available in-process or via a microservice
concierge - integration / interoperability with other NHS software services including patient identity / demographics / staff indexes / PAS / document repositories etc Each underlying system can be viewed through the lens of an open standard - e.g. a HL7 FHIR view.
trud - easy access to NHS Digital’s UK reference data services
nhspd - UK postal code database with links to geographical, administrative and organisational units
Let’s look at two examples in more detail:
hermes makes SNOMED CT available to you easily, so you can embed as a library and run in-process or run as a terminology server. I use this to make it easy to use and make sense of SNOMED CT - both in clinical applications and in my analytics pipelines.
clods allows you to download and make sense of organisational reference data. I use that with the NHS postcode directory (make available via nhspd to find out where a patient lives and make sense of those data - including linking to indices of deprivation. My software applications record the date, time and place of clinical encounters, and can leverage those codes - and so other systems not under my control can understand that a particular encounter occurred at, say, the University Hospital of Wales. Using these data is essential for interoperability.
dmd allows you to download and make sense of drug data in the UK. What kind of drugs is that patient given? How have the doses changed over time? How many milligrams of that ingredient is the patient taking? Is this patient on a type of immunosuppressant drug? This library and microservice takes the NHSBSA dm+d distribution and makes it usable in your applications - whether that’s for clinical care or for running your analytics.
For example, I switch on different functionality in my homegrown EPR based on the diagnoses of a specific patient - e.g. does this patient have a type of motor neurone disease - while doing the same in analytics - e.g. give me all of the patients who have received a type of botulinum toxin - while doing the same in clinical research - e.g. how do the outcomes of multiple sclerosis vary by socioeconomic deprivation?
What’s needed next?
We need to think carefully about how we conceive and build the clinical applications of the future. They should be data-focused, data-driven and made up of a blend of open, modular services.
So what are the shared services that are needed for clinical, administrative and research applications?
There is usually a pattern - usually interesting but often parochial data sources - we need to identify those and make them more usable - by treating them as first-class data products. That means at a minimum, good documentation, persistent non-reused identifiers and simple ways of tracking publication such as a good metadata.
It’s too often the case that governmental data are published on a portal for download, but do not meet these minimum requirements, making it difficult to write software that can recognise publication of a new version and download that latest issue.
After the data, we need easily usable computing services that wrap that data product and make it accessible to applications, irrespective of context. That means building software that provides an API, whether in-process or as distributed microservices.
It is usually necessary to provide different abstractions across these services to make it easier for clients to consume health and care computing services. That usually means providing a ‘view’ of those data in an open standard.
For example, while clods adopts the DCB0090 standard for organisation data, that is a UK standard. Most applications will simply want to make use of organisational data at a simpler, high-level, so I make a FHIR R4 server available with a few lines of code mapping DCB0090 into FHIR to make it simpler to consume.
So I don’t expect client software to understand the different categories of health and care organisation in DCB0090, but we can provide a ‘facade’ across those data to map into data and formats that clients can understand, such as X.500, FHIR or openEHR and provide those data on-demand. So, for example, I can view the NHS Wales’ staff directory in X.500 format (native) or as a facade using a W3C organization ontological view or as a HL7 FHIR ‘view’. It’s all data.
Data are first-class and we should treat data products as first-class as well, together with composable software tools that make using those data products in our applications, whether user-facing for direct care, analytics or research.
Mark
PS. The title of this post alludes to the phrase “Turtles all the way down”, an expression of the problem of infinite regress.
]]>Data analytics using SNOMED CT2021-07-26T15:14:14+01:002021-07-26T15:14:14+01:00https://www.wardle.org/snomed/2021/07/26/making-valuesetsThere’s a problem with using SNOMED CT for data analytics; in this post, I’ll explain the issue and how to mitigate! If you’re using SNOMED CT for data analytics, you will encounter this issue, and need to handle it!
Data analytics using SNOMED CT
Imagine I’m building a real-time analytics pipeline for patients with multiple sclerosis.
I need to understand patient outcomes - and that means we need to define patient data into cohorts.
A cohort is a group of patients with shared characteristics.
That cohort might be defined by diagnosis, by treatment type, by age, by gender, by geography, by levels of socio-economic deprivation, or by something else.
SNOMED CT is a sophisticated and comprehensive clinical terminology that provides codes representing many of these characteristics. SNOMED is special because
it isn’t simply a flat list of codes, but instead it is an ontology. As a result SNOMED defines concepts and the relationships between them.
For example, it defines multiple sclerosis as a type of demyelinating disorder. This means, used properly, I can not only search health and care
data for patients with multiple sclerosis, but I can also search for demyelinating diseases and patients recorded as having multiple sclerosis will be
included in that cohort simply as a result of the SNOMED ontological hierarchies. I don’t need end-users to record a diagnosis of demyelinating disorder,
but I can search for that and include all disorders that are a sub-type of that disorder.
I can do the same for drugs in SNOMED CT - so I might want to search for drugs that contain, say, Glatiramer acetate - an immunological drug used in multiple sclerosis. Because the UK drug extension for SNOMED CT includes relationships such as “Has specific active ingredient”, it is straightforward to use SNOMED
CT to slice and dice our health and care data in order to make valuable inferences.
Hermes
Hermes is an open-source terminology server that I wrote.
You can have your own server running in minutes by following the instructions, or use my demonstration links below. It can even download and install SNOMED automatically if you live in the UK.
It can also provide a FHIR terminology server API via hadex.
Hermes operates as a library, or a microservice. It is designed to be immutable once running - so that we might have services running providing different versions of SNOMED CT, each load-balancing. Other terminology servers do not use this approach, but instead update-in-place, with management of versions within the same terminology. I prefer multiple small services and switch at the API gateway level, or reverse proxy to different versions, all of which run independently.
The SNOMED CT expression constraint language
The specification for the SNOMED CT expression constraint language (ECL) is available here.
It’s a way of defining a set of SNOMED CT concepts.
Here’s a simple example:
<< 73211009 |Diabetes mellitus|
This means, give me a set of codes that represent diabetes mellitus, including its sub-types. You can see the codes this expands to here.
When I am building a user interface component to allow a pop-up and autocompletion box, for say, country of birth, I might search based on
the text the user has entered and limit the search to the set of concepts defined by:
<370159000|Country of birth|
This will mean a search for “Cro” will give me “Born in Croatia” but exclude “Crohn’s disease”.
[{"id":459924011,"conceptId":315409004,"term":"Born in Croatia","preferredTerm":"Born in Croatia"}]
I wouldn’t want to record a diagnostic term in a field that should only record concepts that are a sub-type of country of birth. I can both configure and validate user input.
You can think of ECL as providing a quick and easy way to define a set of codes that you’re interested in. In essence, it builds codelists - a subset of codes which can be used or searched.
As you might expect, you can use boolean logic in an expression to
combine different terms. For example, if you’re searching for patients who have reduced splenic function you might use
<<234319005|Splenectomy| OR <<23761004|Hyposplenism|
I use the combination of a user-entered search string (e.g. “MND”) and a constraint to help users enter information in a context-appropriate way - e.g. by type, or by membership of a reference set etc.
Building code lists
In summary, we can use the expressions to realise a codeset. For example,
we might want to build a list of diagnoses that are a type of neurological disease, suitable for use when interrogating data sources for an audit or for research.
In HL7 FHIR, the operation to turn an expression like this into a value set is called expansion.
So what’s the problem?
SNOMED CT is an evolving clinical terminology. That means it is updated, refined and changed over time. Fortunately, concepts are never deleted, and
identifiers are never re-used, but concepts can be inactivated.
When this happens, all of its relationships are removed.
What this means in practice is that a now-outdated or redundant concept will not be found when we use the SNOMED CT relationships to define an interesting
set of codes!
Let’s look at an example related to multiple sclerosis.
So we want all patients who have multiple sclerosis?
Won’t the codes we need will be included in the result of:
<< 24700007
That means give me the concept 24700007 and all of its descendants (sub-types). Have a look at the results here.
No it won’t!
Have a look at 24700007 in the SNOMED online browser - and start clicking on the children and
the children of those children. The expression ‘«24700007’ will, in essence, return all of them for you in an instant.
Legacy data!
But let’s look at our legacy data. In our electronic health and care record, we have some old data that includes the concept 155023009 - this is an outdated, inactive concept representing multiple sclerosis, and it won’t be found using <<24700007! It won’t be found because inactivated concepts don’t have any active relationships.
This a problem!
That patient, just because they’ve been recorded as having multiple sclerosis using a term now inactive, potentially won’t show up in our dataset! This isn’t an uncommon scenario; and it is a problem that will increase as more health and care software uses SNOMED CT.
What are the potential solutions?
There are four options:
Highlight now inactive concepts in our dataset and manually update to the modern equivalents ie. fix our source data manually by flagging to end clinical users. Fix the problem by fixing our source data.
When processing our dataset, highlight inactive concepts and append the modern replacements or equivalents.
When generating searches, include outdated concepts in the code lists.
Provide easy access to multiple versions of SNOMED CT, selectable at runtime, so that inferences can be made based on the date the data were entered at each point.
There are a variety of trade-offs for each option but each can make use of the historical
association reference sets that are provided as part of SNOMED CT.
An historical reference set provides a linkage between a now-outdated concept and what it might be better represented as nowadays.
Unfortunately, this isn’t as simple as it might sound. Some concepts are genuinely now regarded as wrong - or may be better represented using one of many more specific terms. Imagine a disease we used to think of as a single entity, but now realise that diagnostic entity is better represented
as one of three different more specific entities, that might or might not
be exactly equivalent?
Here are some example reference sets that will help us:
Name Concept identifier
REPLACED-BY 900000000000526001
SAME-AS 900000000000527005
POSSIBLY-EQUIVALENT-TO 900000000000523009
The simplest is REPLACED-BY. There’ll be a 1:1 mapping between an old concept and a new concept if there is one that is conceptually REPLACED-BY the new one! But some concepts are truly outdated, and there will be some ambiguity in how to use that now outdated term.
[{"id":900000000001151017,"conceptId":900000000000523009,"term":"POSSIBLY EQUIVALENT TO association reference set","preferredTerm":"POSSIBLY EQUIVALENT TO association reference set"},{"id":900000000001152012,"conceptId":900000000000524003,"term":"MOVED TO association reference set","preferredTerm":"MOVED TO association reference set"},{"id":900000000001154013,"conceptId":900000000000525002,"term":"MOVED FROM association reference set","preferredTerm":"MOVED FROM association reference set"},{"id":900000000001157018,"conceptId":900000000000526001,"term":"REPLACED BY association reference set","preferredTerm":"REPLACED BY association reference set"},...
When operating interactively, we can ask our user to resolve ambiguities and map to a more modern term.
But what about for analytics? We might be processing millions of health records in which it will not be practical to update legacy terms by hand.
We are left with two options:
Pre-process each health and care record mapping legacy terms to modern equivalents.
Pre-process our searches, valuesets and code lists so that they include legacy inactive concepts as well as the modern equivalents.
Pre-process the health and care record
For our inactive term, in our data pipeline, we could look for
this concept’s historical association reference sets and include some or all of the modern replacements in-place.
We then perform analysis on a modified patient record that has been updated to use only active terms.
We can do this easily by identifying now inactivated concepts, and following the historical associations for that concept.
Let’s try a worked example:
You can see that 155023009 is inactive - and you can see the same via hermes:
This end-point picks out only the historical association reference set types and lists them conveniently keyed by the association reference type. This makes it straightforward to follow SAME-AS, REPLACED-BY or POSSIBLY-EQUIVALENT-TO links.
So here we see that 155023009 is linked to 24700007 by virtue of a SAME-AS definition - 900000000000527005.
Pre-process our searches, valuesets and codelists
Alternatively, when we’re generating a list of codes for our code list, we could reverse this process and look at the modern concept(s) in which we are interested and get back the legacy inactive identifiers that we want to include.
We can ask hermes to expand any arbitrary SNOMED expression constraint language (ECL) expression:
You’ll see that our expanded codelist now also includes outdated, inactivated concepts from past versions of SNOMED. We can now use this expanded list for our data analytics.
Managing real-life health and care data is complex; health informatics needs to build software, ideally open-source, that manages some of these complexities. Open-source tools are ideal, because we create a shared community.
Hermes is a library and microservice that provides some of that capability in relation to SNOMED CT and other terminologies.
You cannot ignore the issue of managing codes now thought of as inactive, or outdated from your health and care data, but instead you need to think carefully about how to manage change over time.
Hermes provides a number of ways of managing those changes including versioned distributions, methods to identify and understand how to map outdated concepts to modern equivalents, to methods to create codelists based on expressions that optionally include historical equivalents of their members.
Mark
]]>A mistake at REST2021-06-30T16:07:08+01:002021-06-30T16:07:08+01:00https://www.wardle.org/ehr/2021/06/30/mistakes-at-restThe HL7 FHIR standard provides a useful model of health and care information, but it is a specification from which a local standard can be built via profiling. It defines models of data and a specification for how to exchange those data via an architectural pattern called representational state transfer (REST). While there are other ways that data in HL7 FHIR can be exchanged, using REST as an architectural pattern means that software using HL7 FHIR for data exchange will read and write to resources that represent something in the health and care domain.
Immutability refers to an approach to software engineering in which data are unchangeable.
Such an approach is particularly suitable when considering medical
records and processes. Indeed, from a medico-legal perspective, all data should
be regarded as immutable as it is usually necessary to be able to view the state of
the record at any point in time.
New records update and take the place of older records in our decision-making, but those
older records still exist.
Of course, most implementations will not actually delete data when when we issue a DELETE against a resource.
For example, if we issue a DELETE against a resource representing an organisation in our health and care environment,
the underlying software is likely to effect that change by simply marking that organisation as deleted.
So what’s the issue?
It’s that thinking that the model of data that we use to examine, process and make sense of a health and care record
is the same as the one that might populate that medical record in the first place.
Different models for reading and writing
The problem is that the modelling of information used for reading is widely different to that information we record
as a consequence of the processes of care.
The medical record is not simply a record, but a working tool that helps professionals and patients make sense and
reduce the uncertainty about a decision, whether that decision is about an individual patient (shall I have that procedure?),
a clinical service (how do we configure our service to best improve outcomes?) or for research (what new knowledge can we gain?).
“You’re a victim of it or a triumph because of it. The human mind
simply cannot carry all the information without error so the record
becomes part of your practice.”
Dr Larry Weed, Internal Medicine Grand Rounds, 1971
In other complex domains, a pattern of command query responsibility separation (CQRS) has been used in which
the information models of querying (reading) data are separate from those of creating data.
I would argue that for many situations in health and care, we should build quite different data models for issuing “commands”
or “actions” than the data models I subsequently use in order to make sense of the record.
We should move away from REST semantics towards separating how we think about commands from how we think about queries.
For example, I prescribe a drug (an action) and that data model, that domain event, is used to populate a view (a query) of all recently prescribed drugs and provide a flattened ‘view’ of a medication list based on those actions. I am not reading and writing a medication list, but the list is built as a consequence of the actions.
This approach scales well to the medical record, because the medical record should be dominated by reads. That means it is very easy to optimise reading and processing of data differently to the systems that handle writing.
It also simplifies our data modelling work - because we can build clinical data models that focus on workflow and process (our actions), and then separately conceive of the best ways to make sense and view the logical record - quite rightly through different ‘prisms’ depending on need.

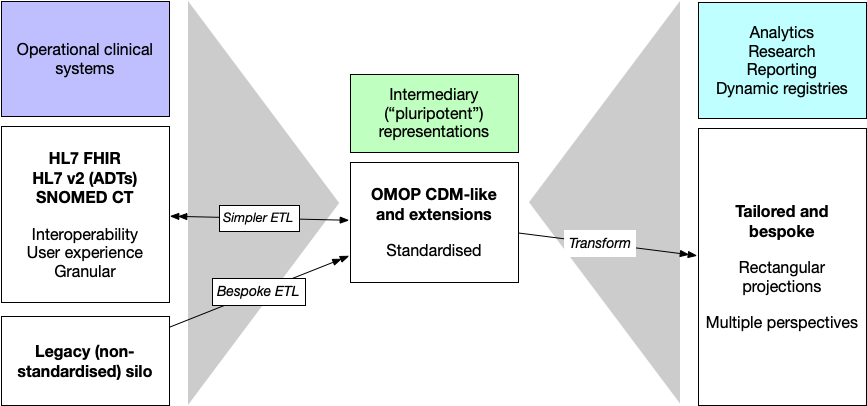



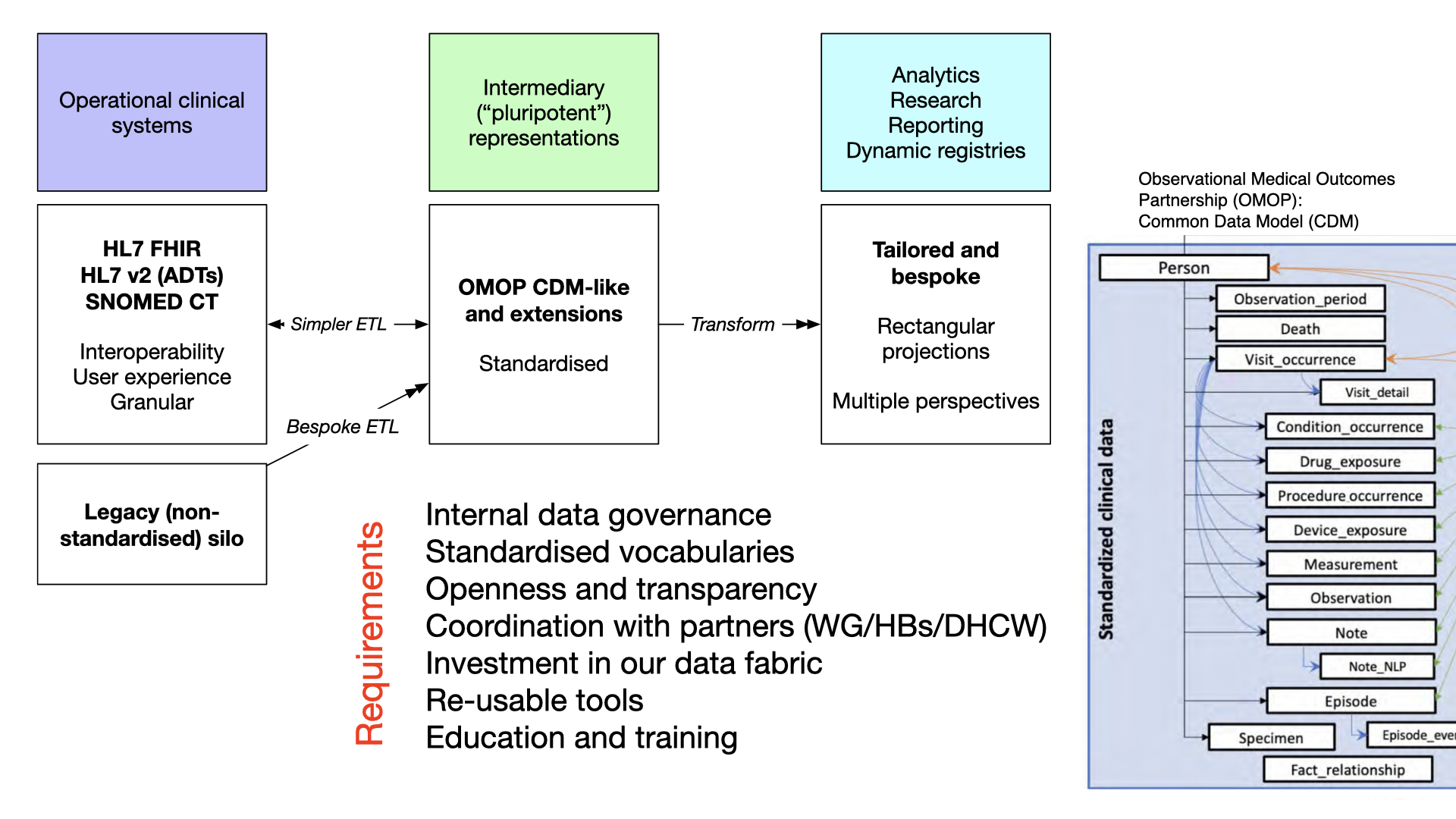


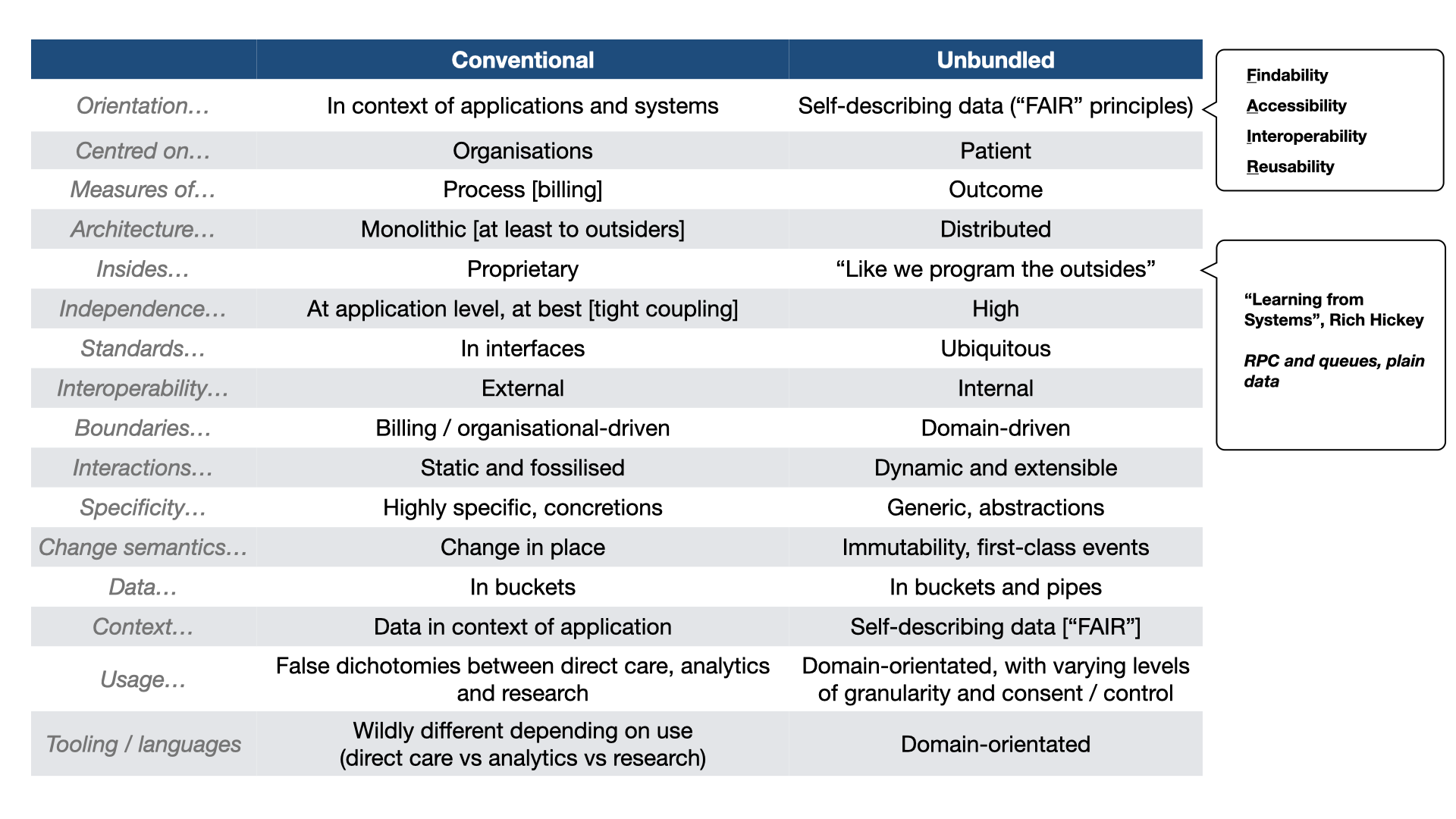
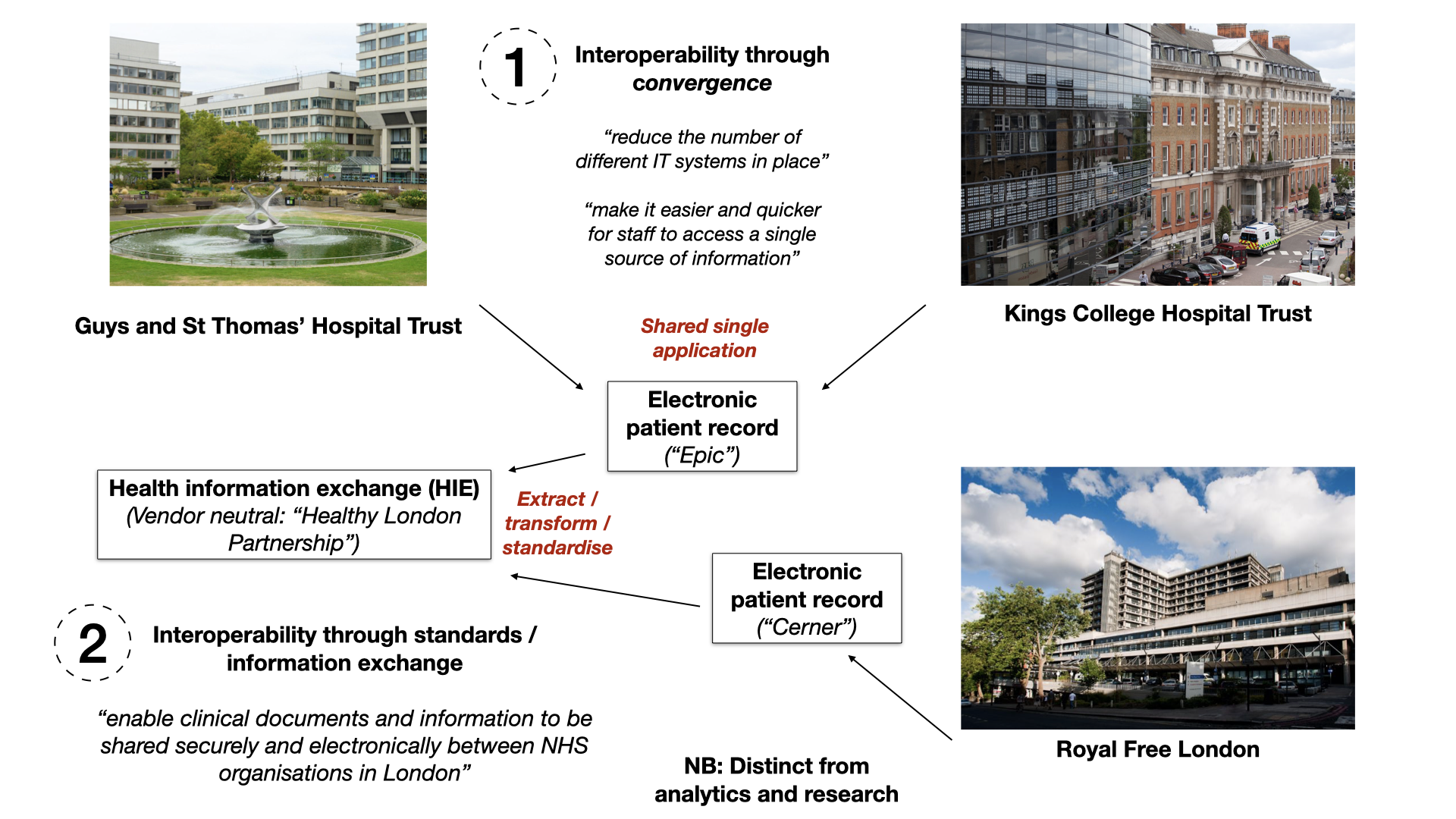
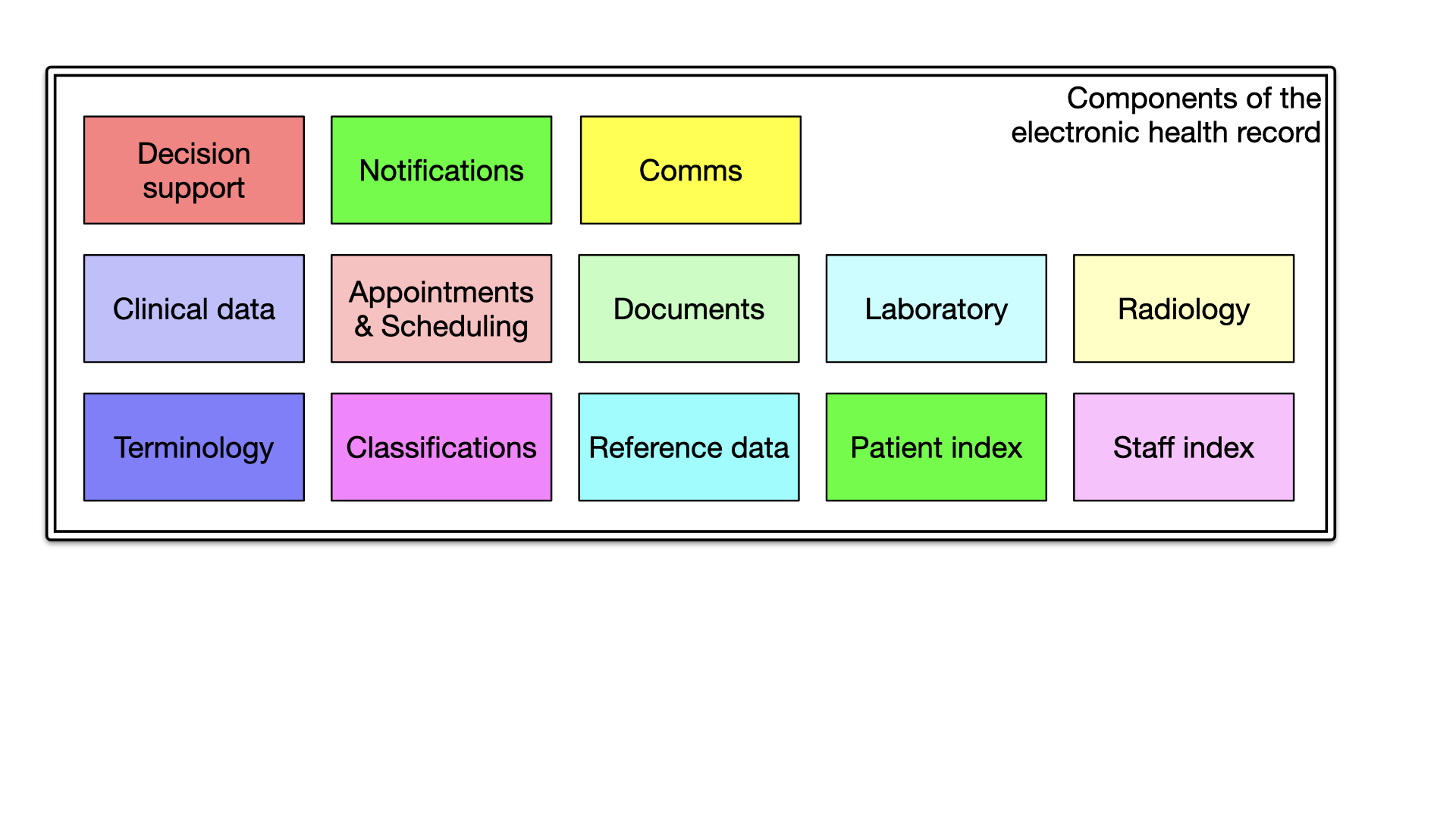
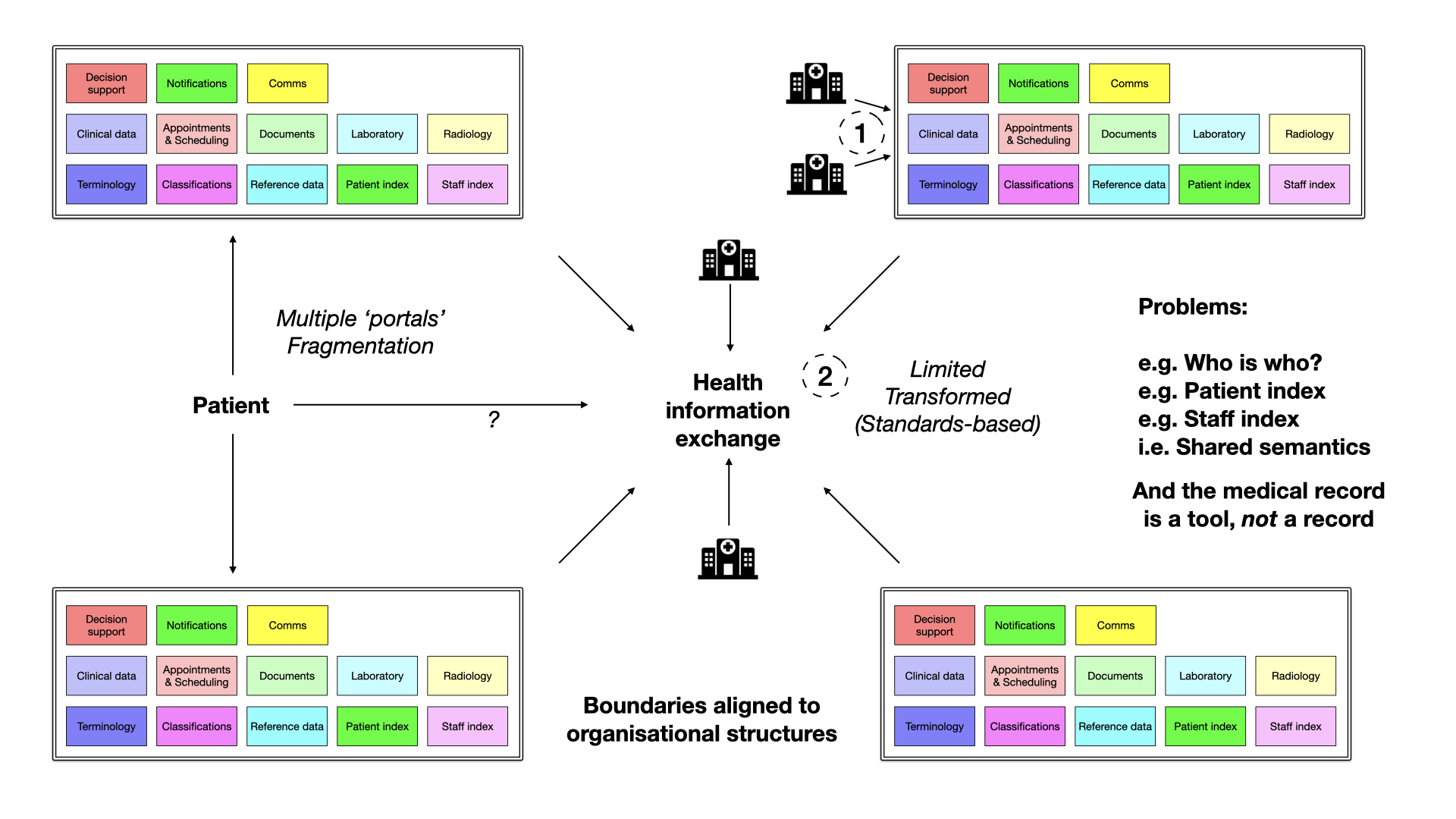
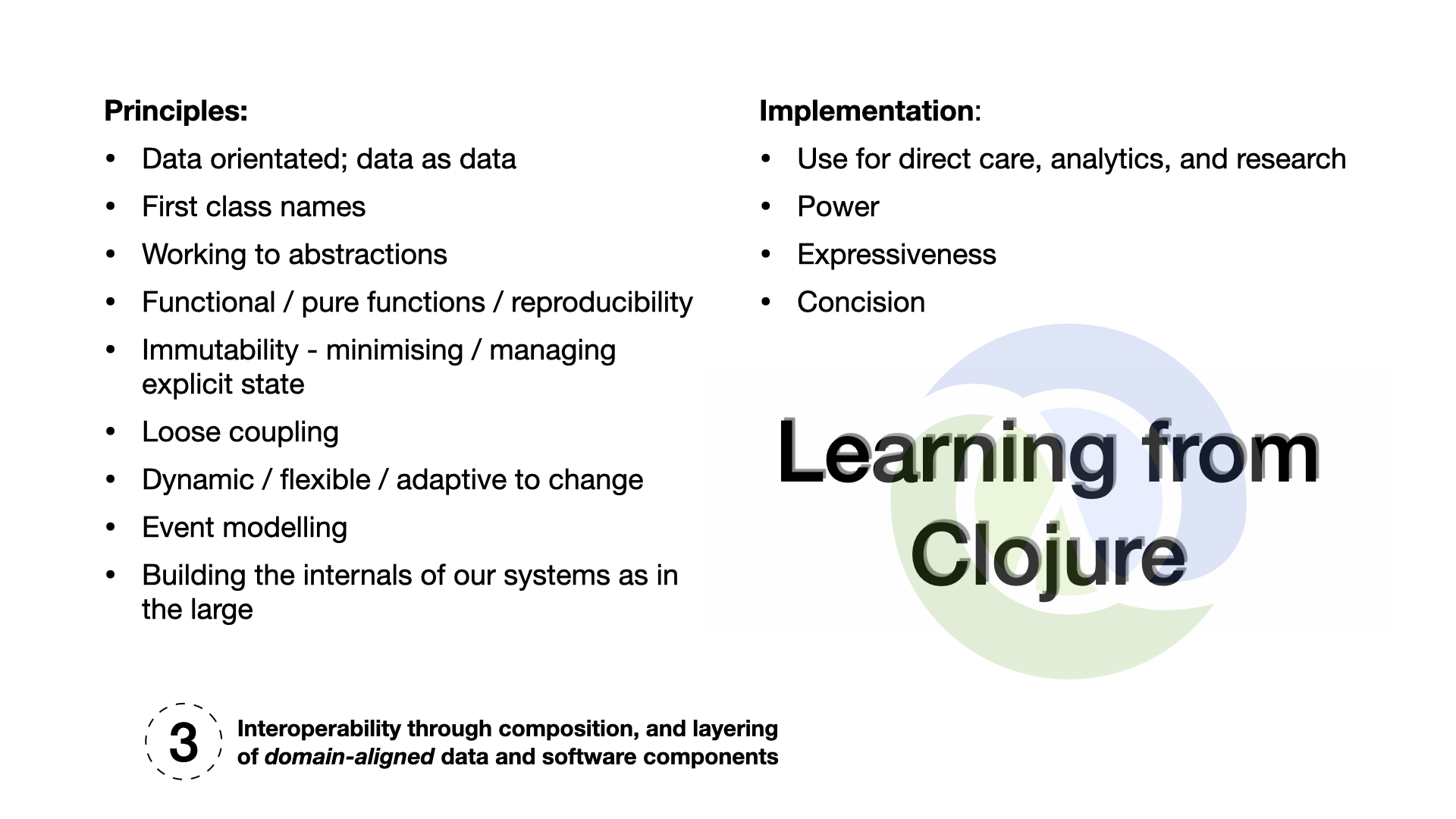
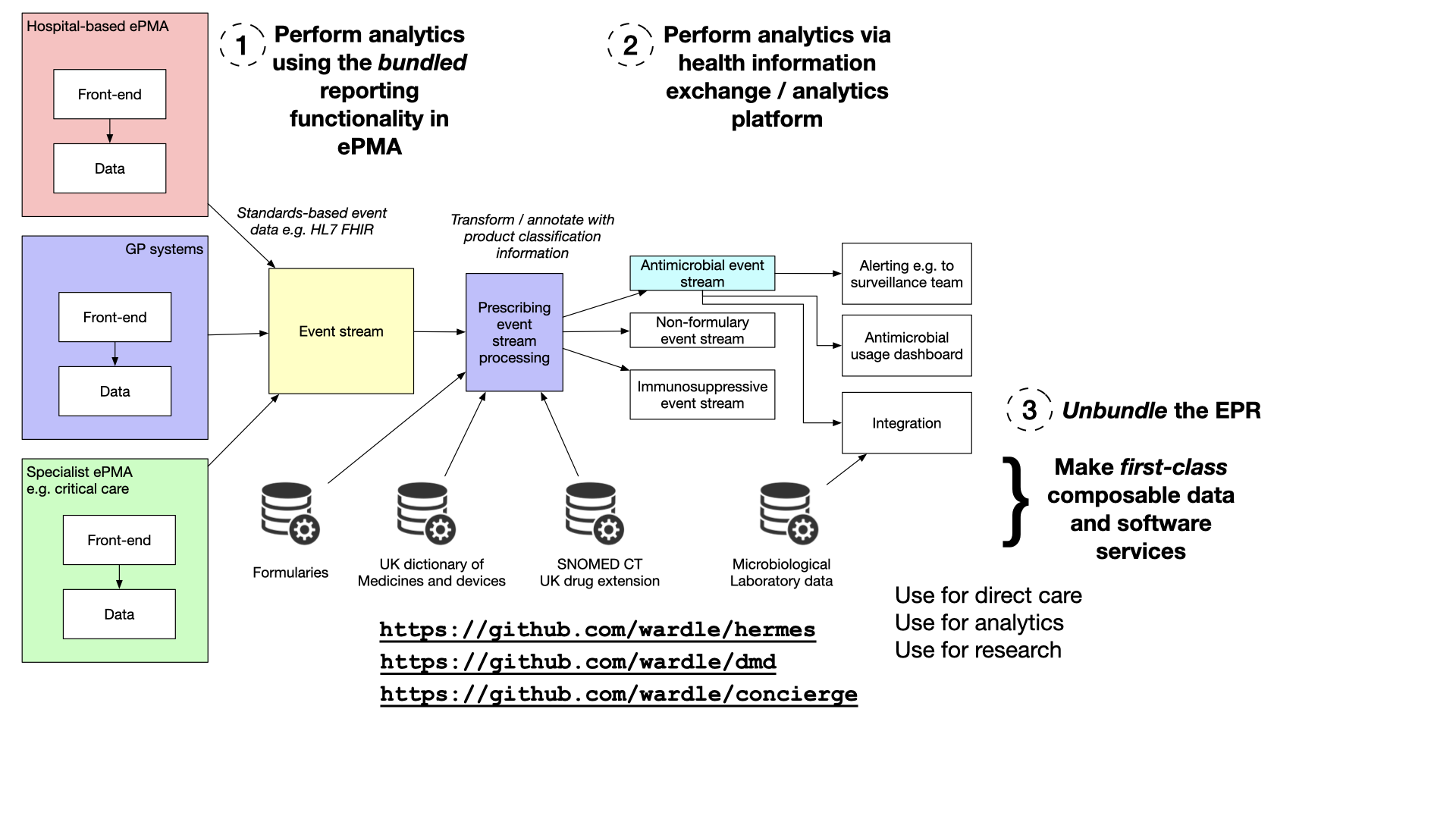
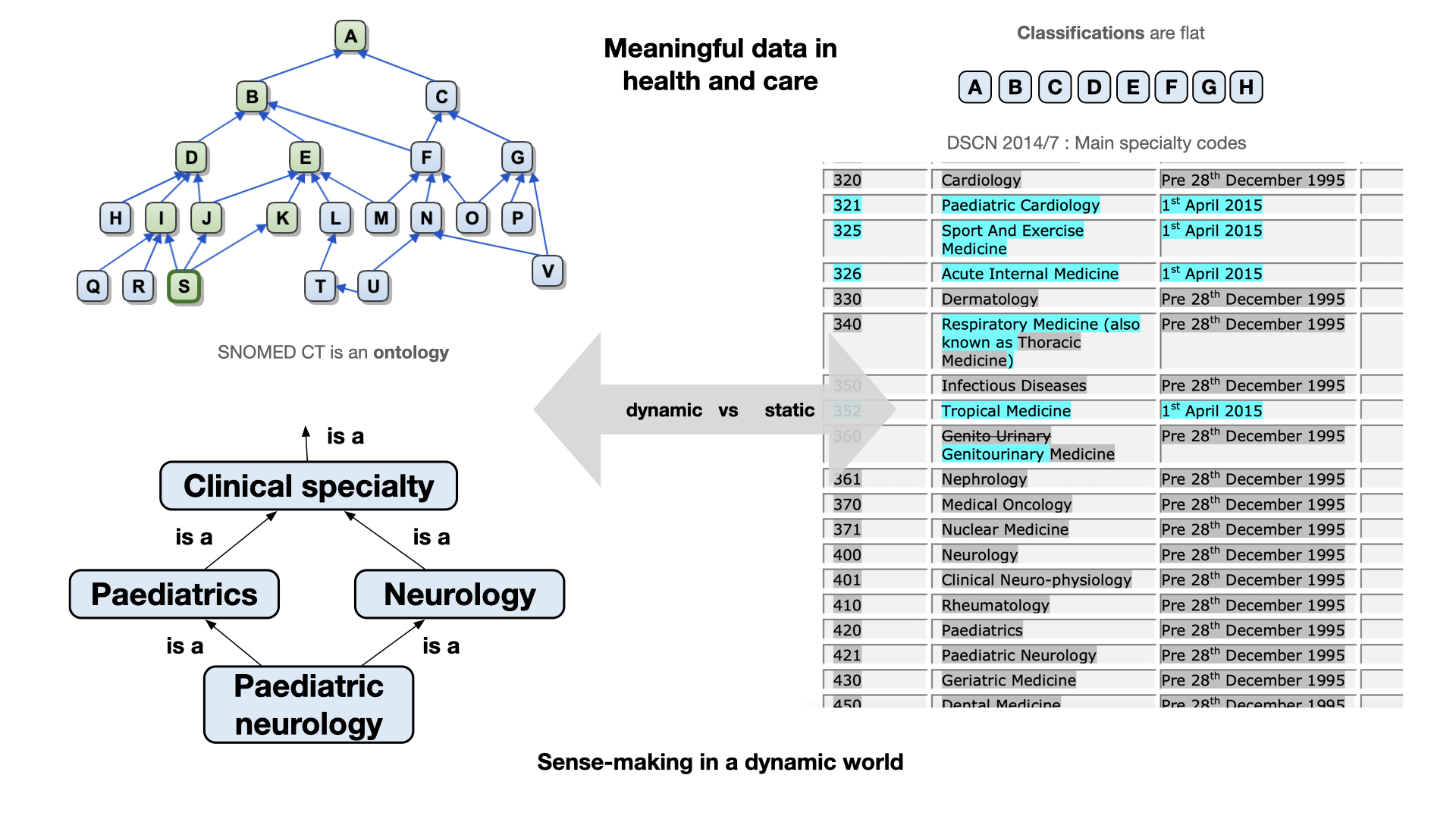
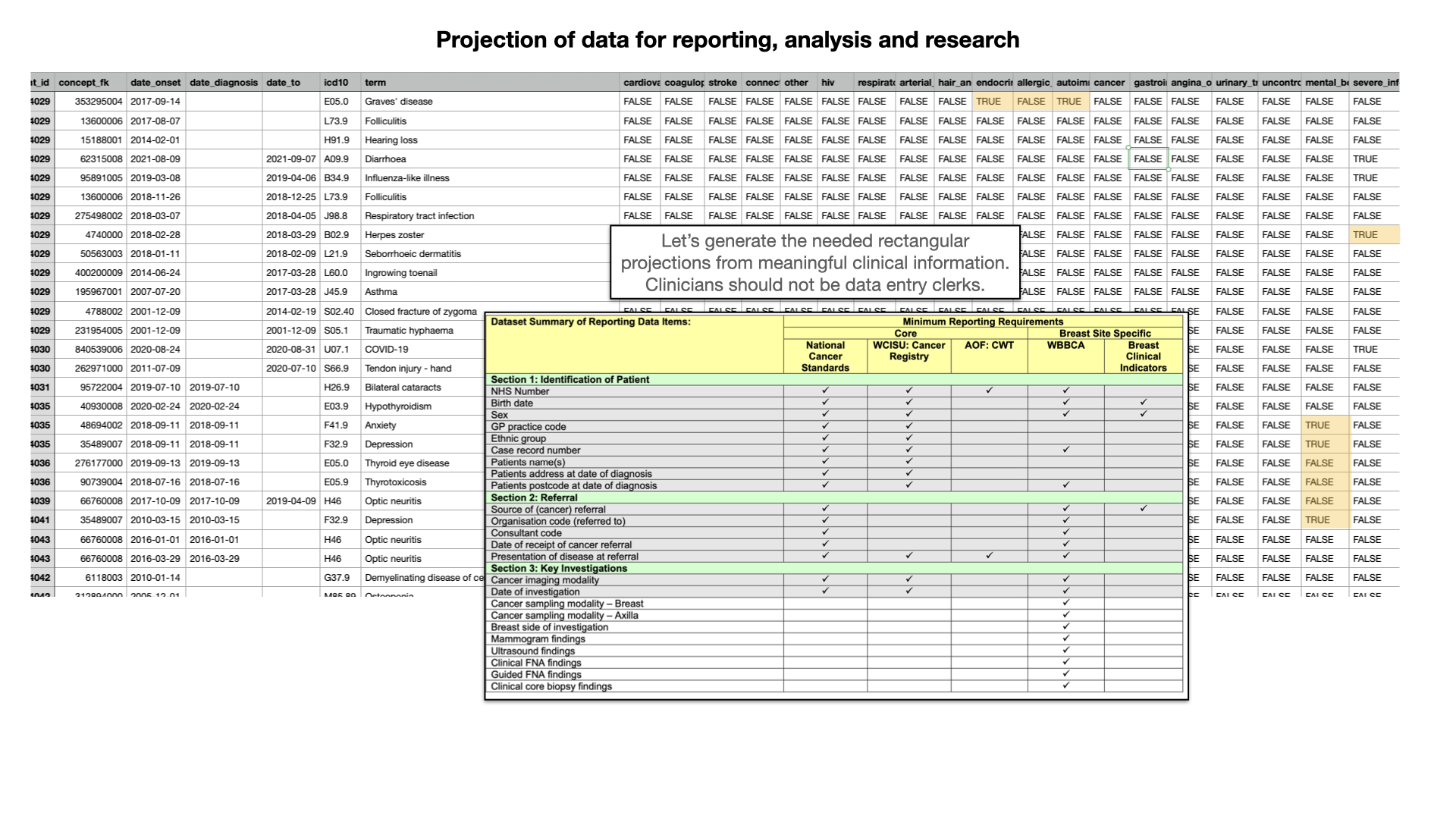
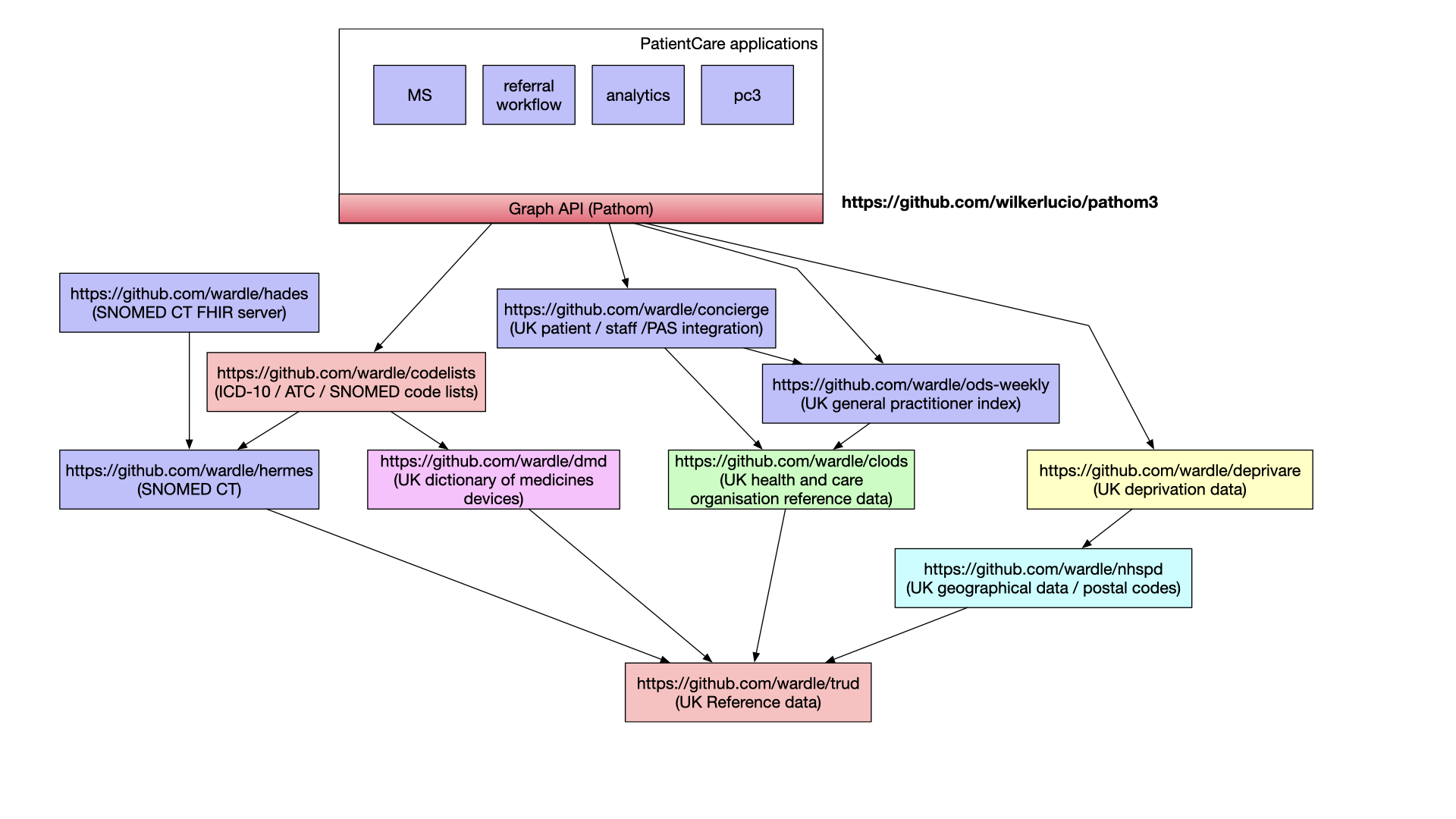
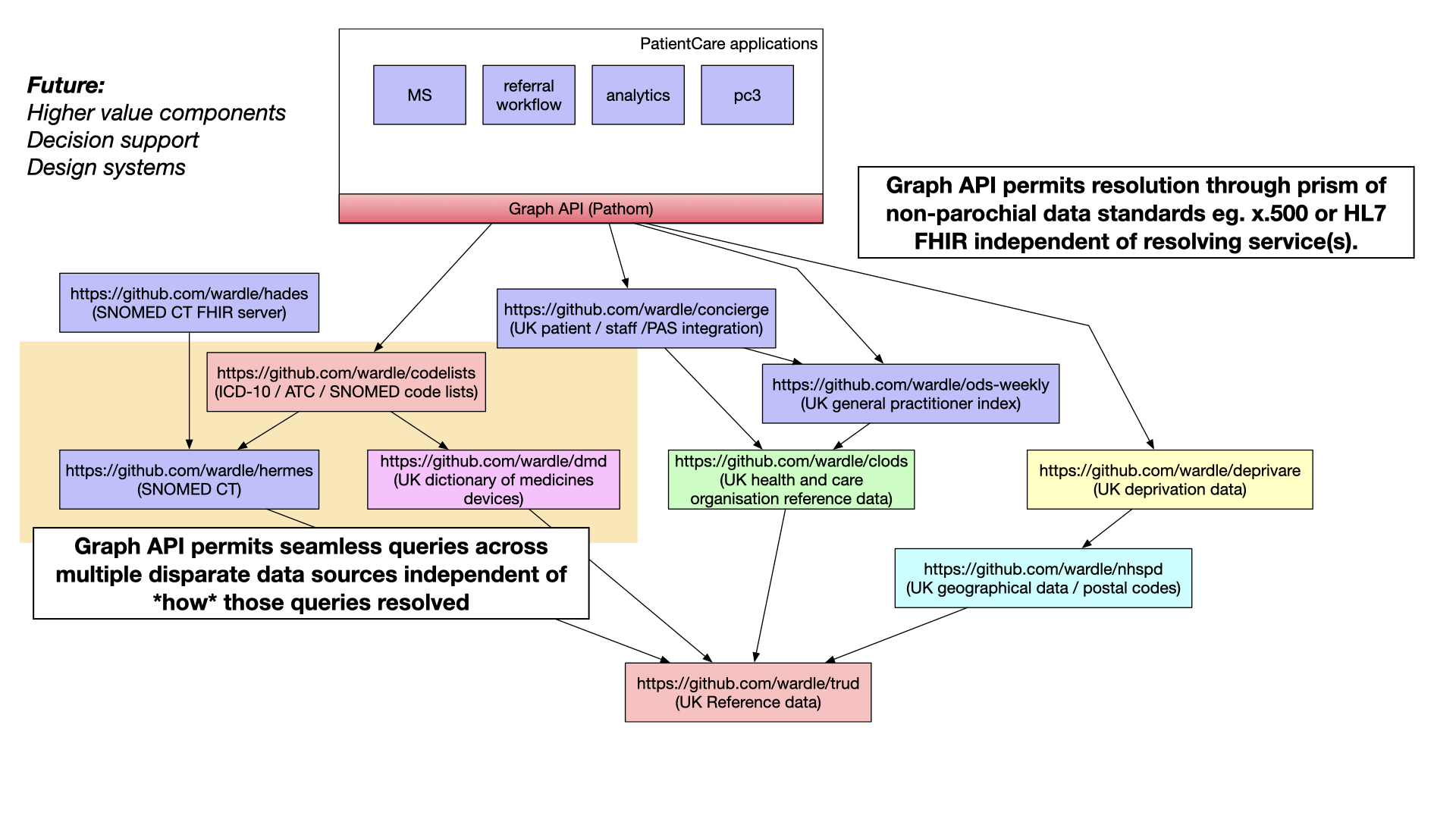


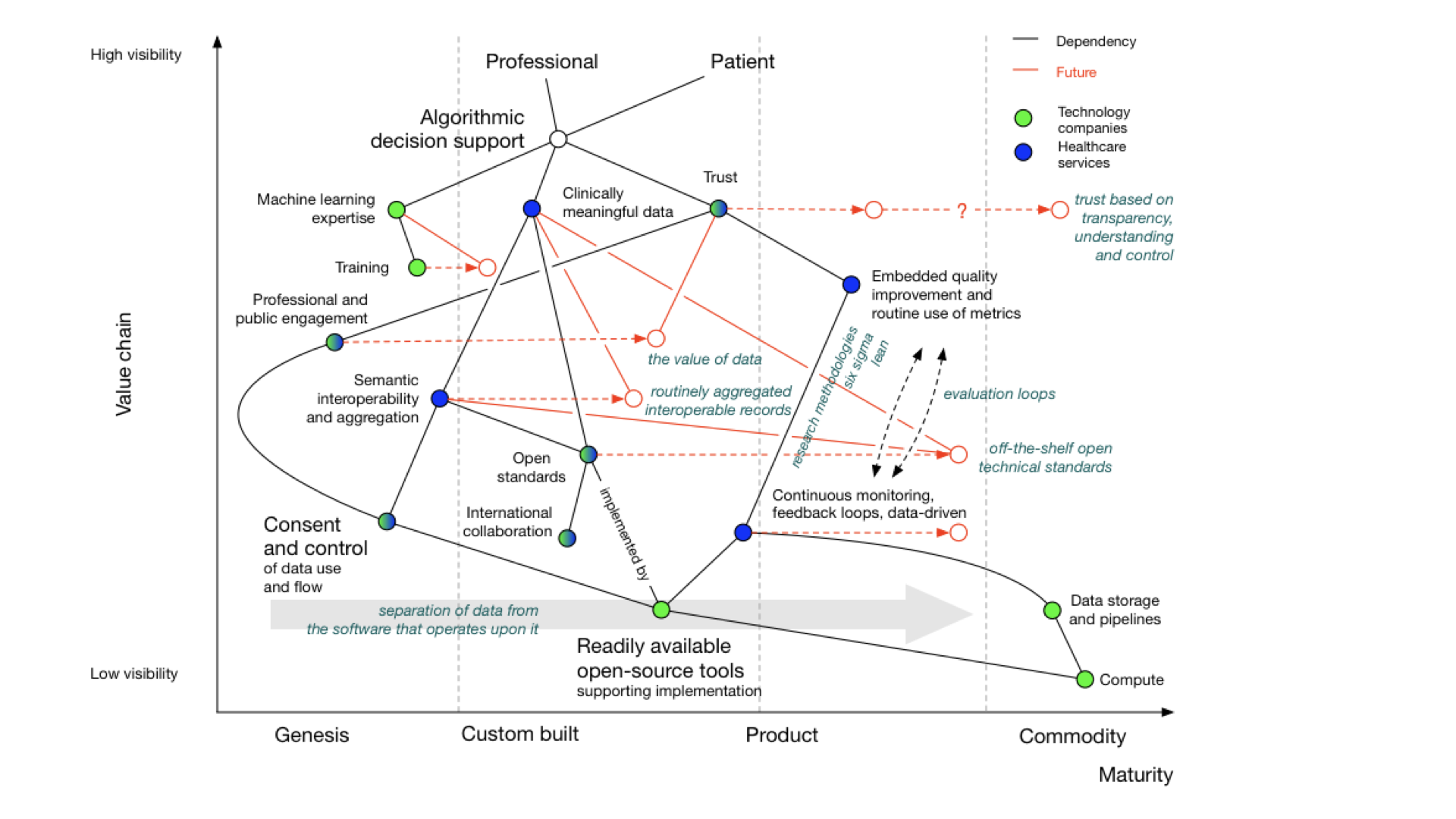
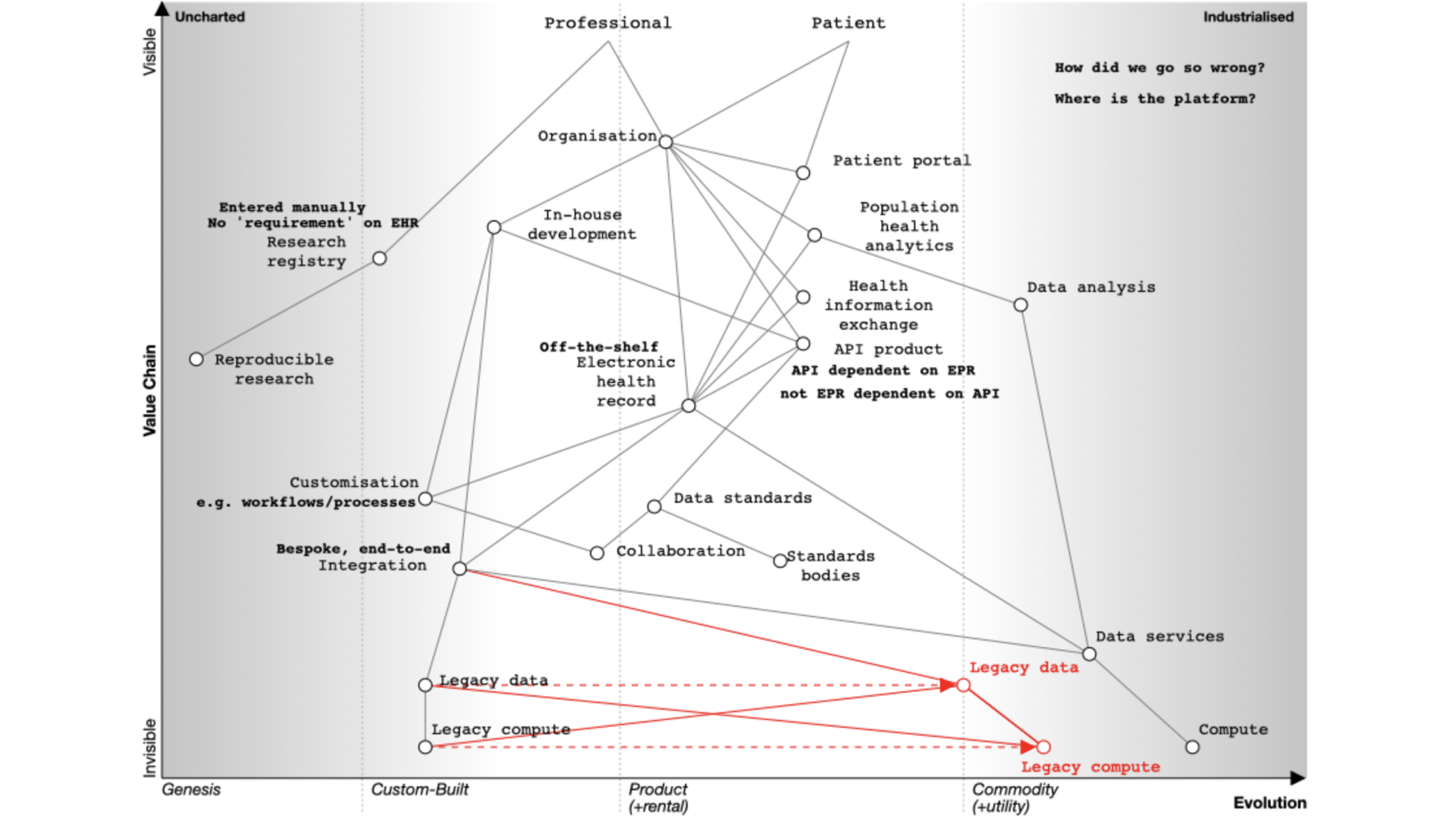
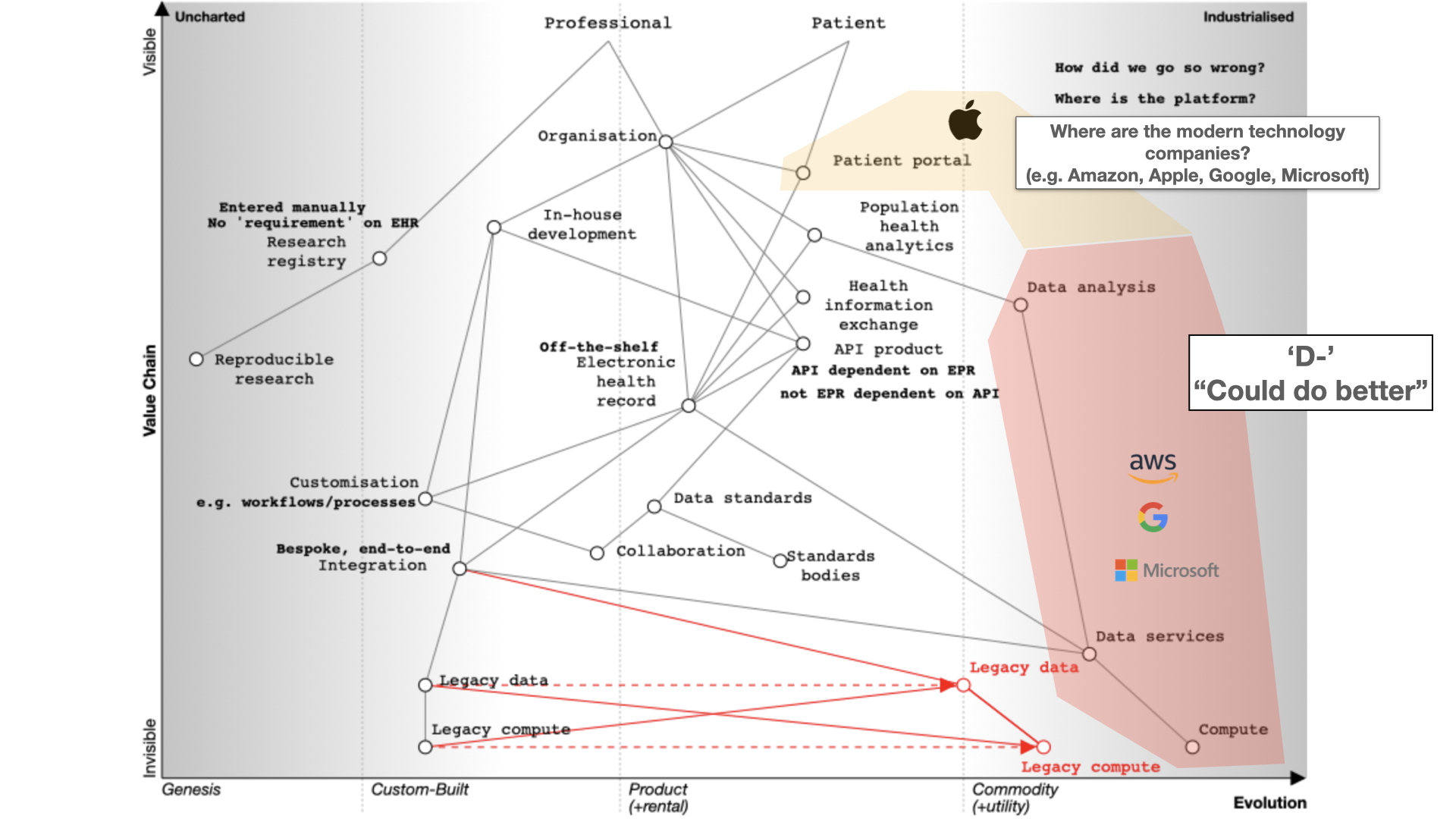
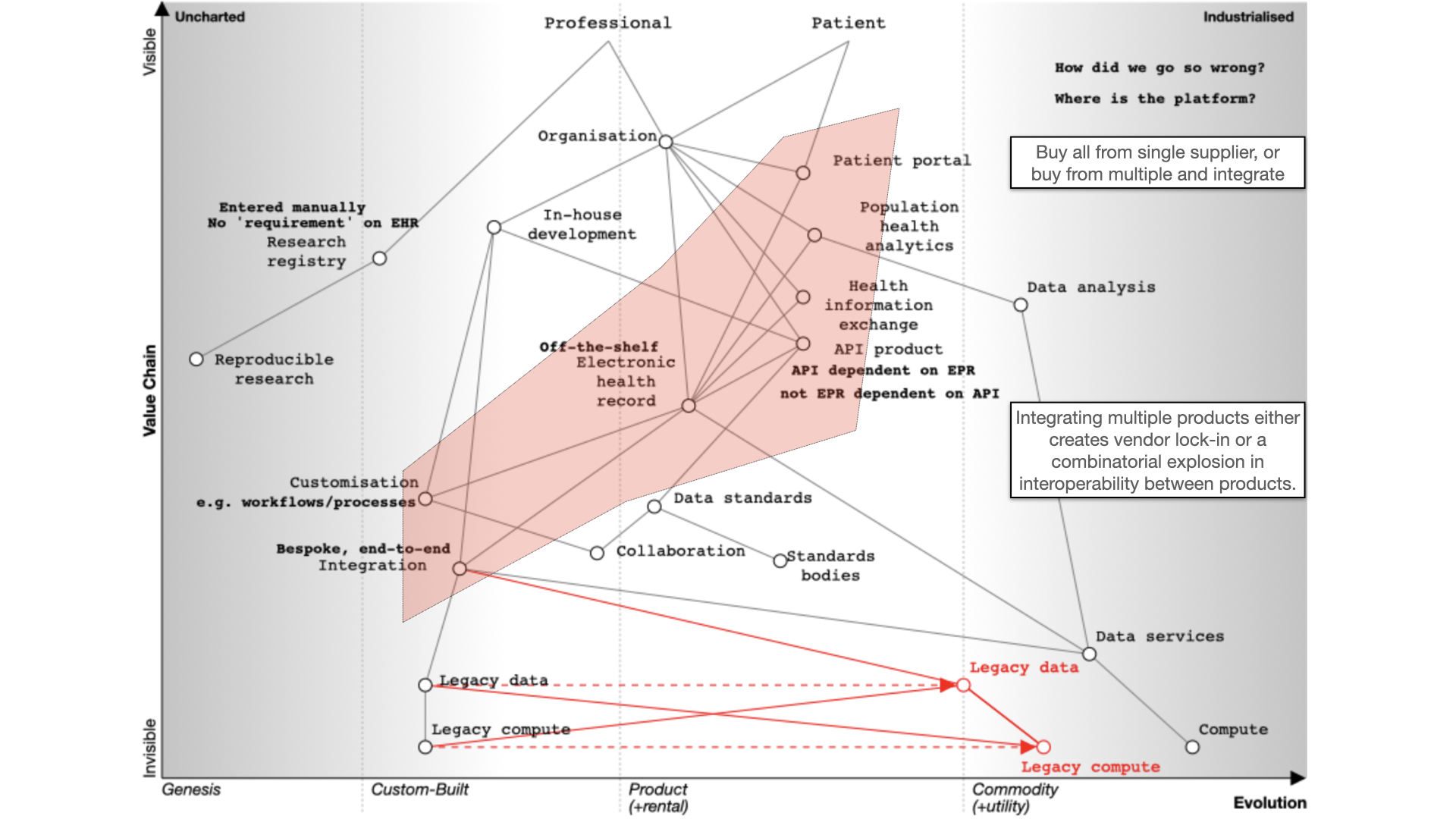
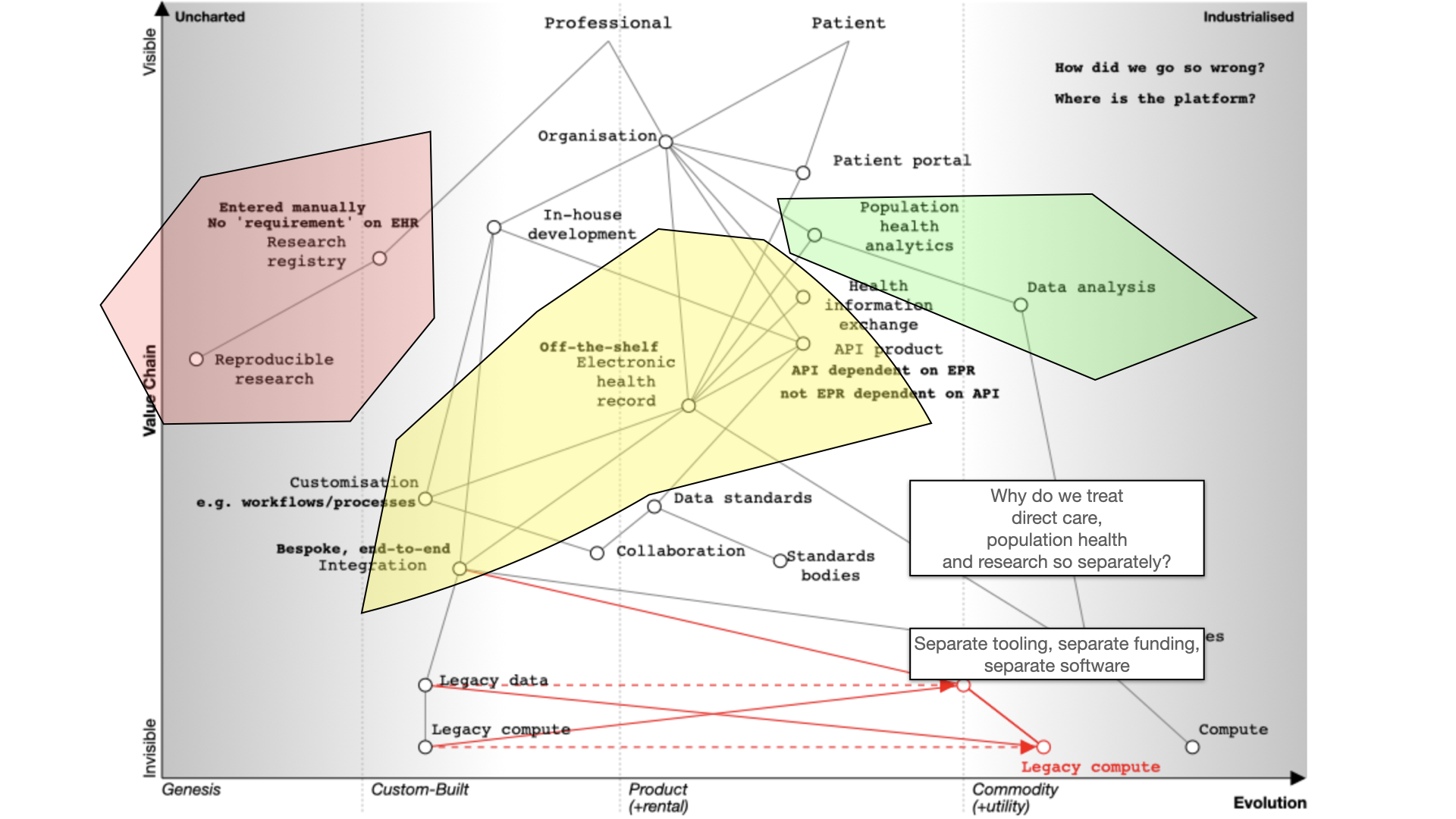

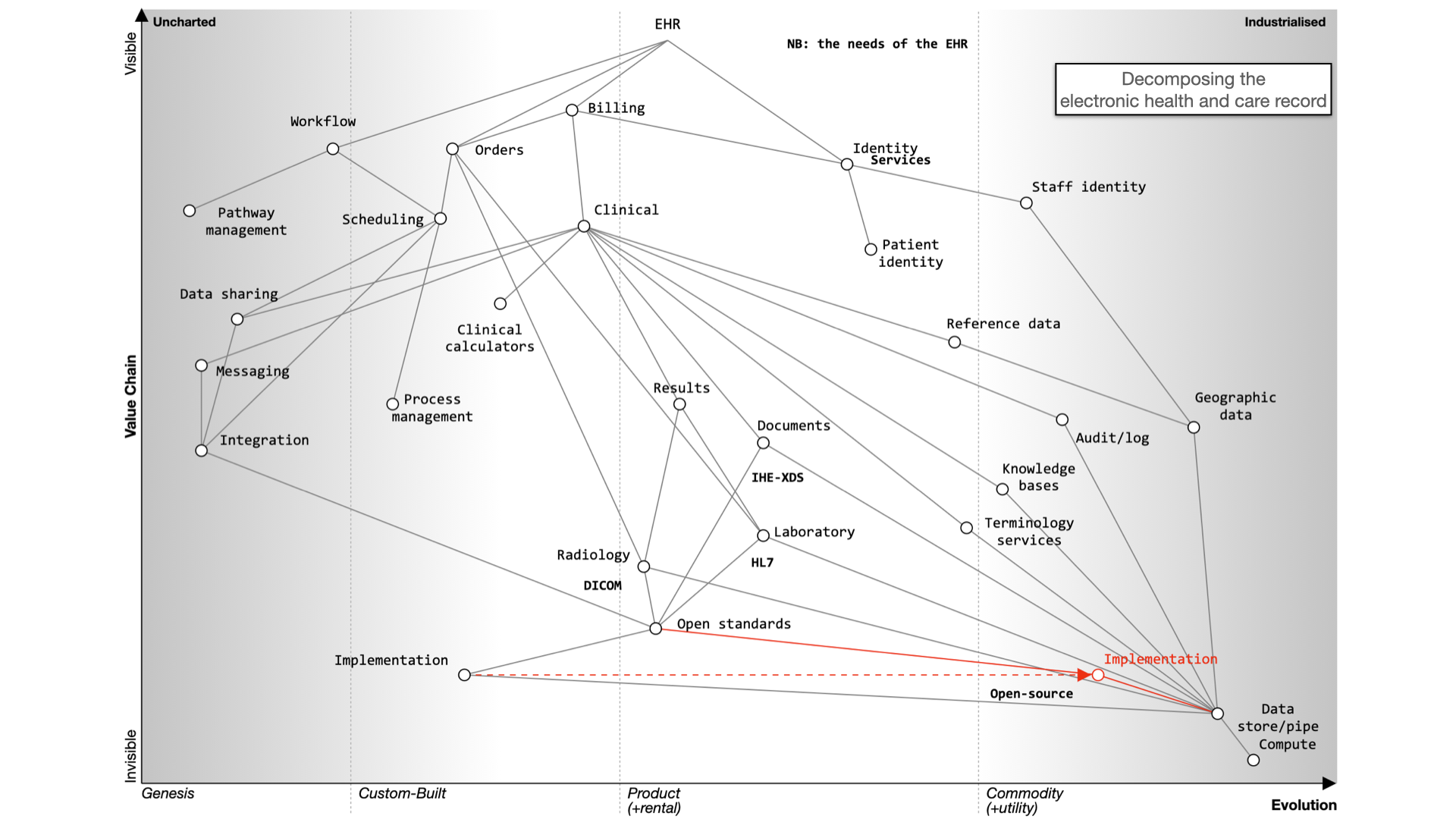
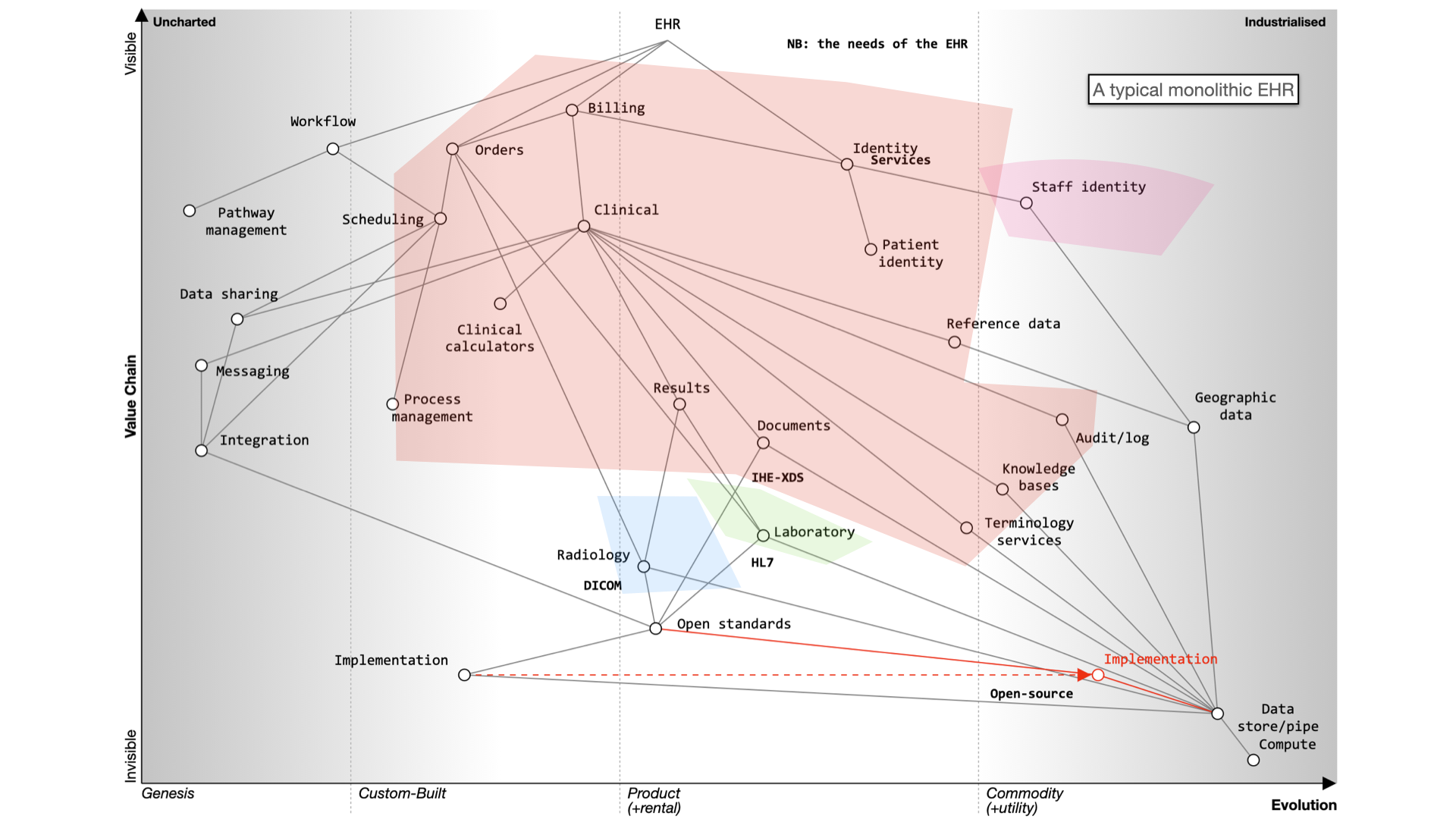
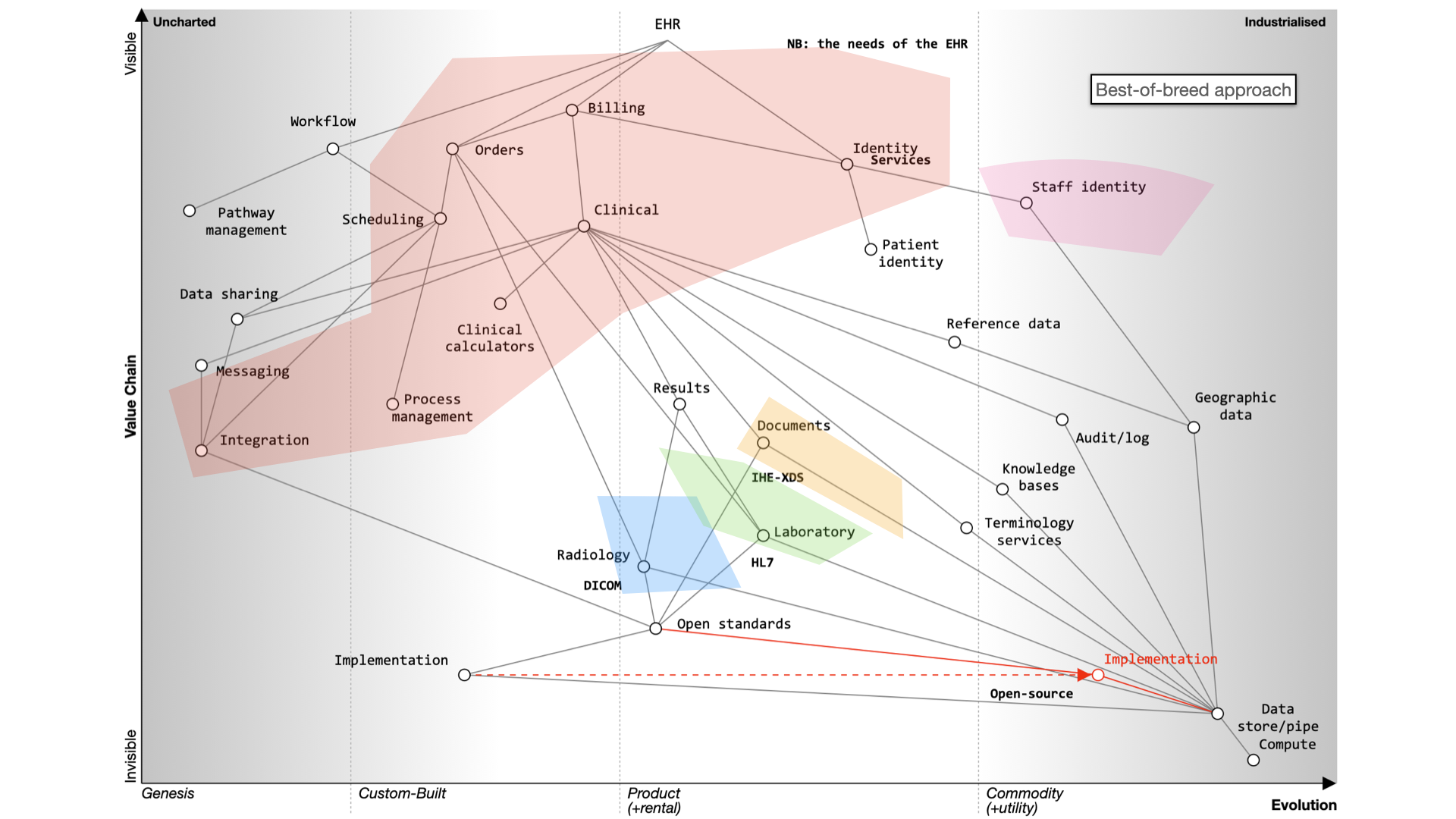

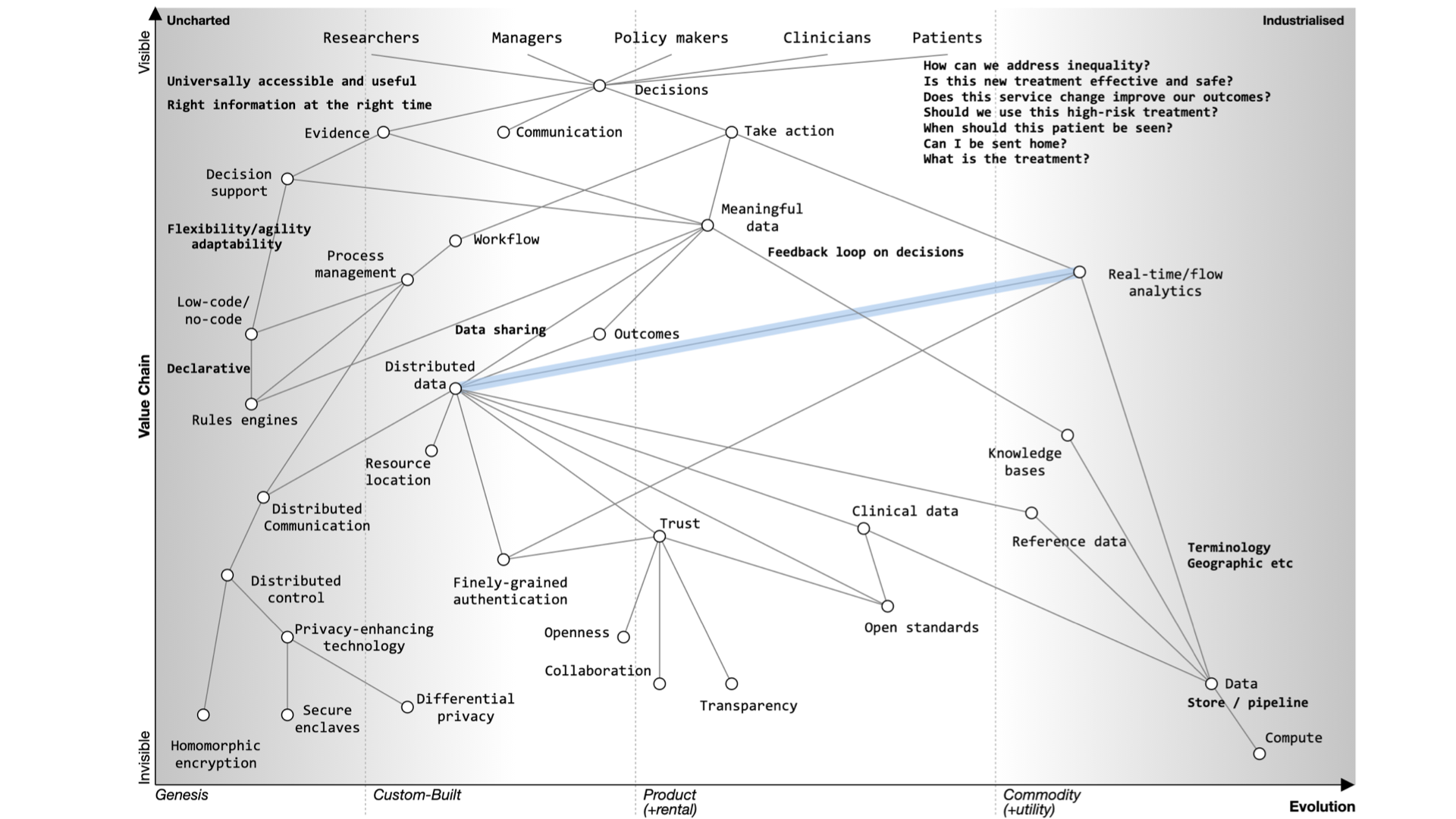
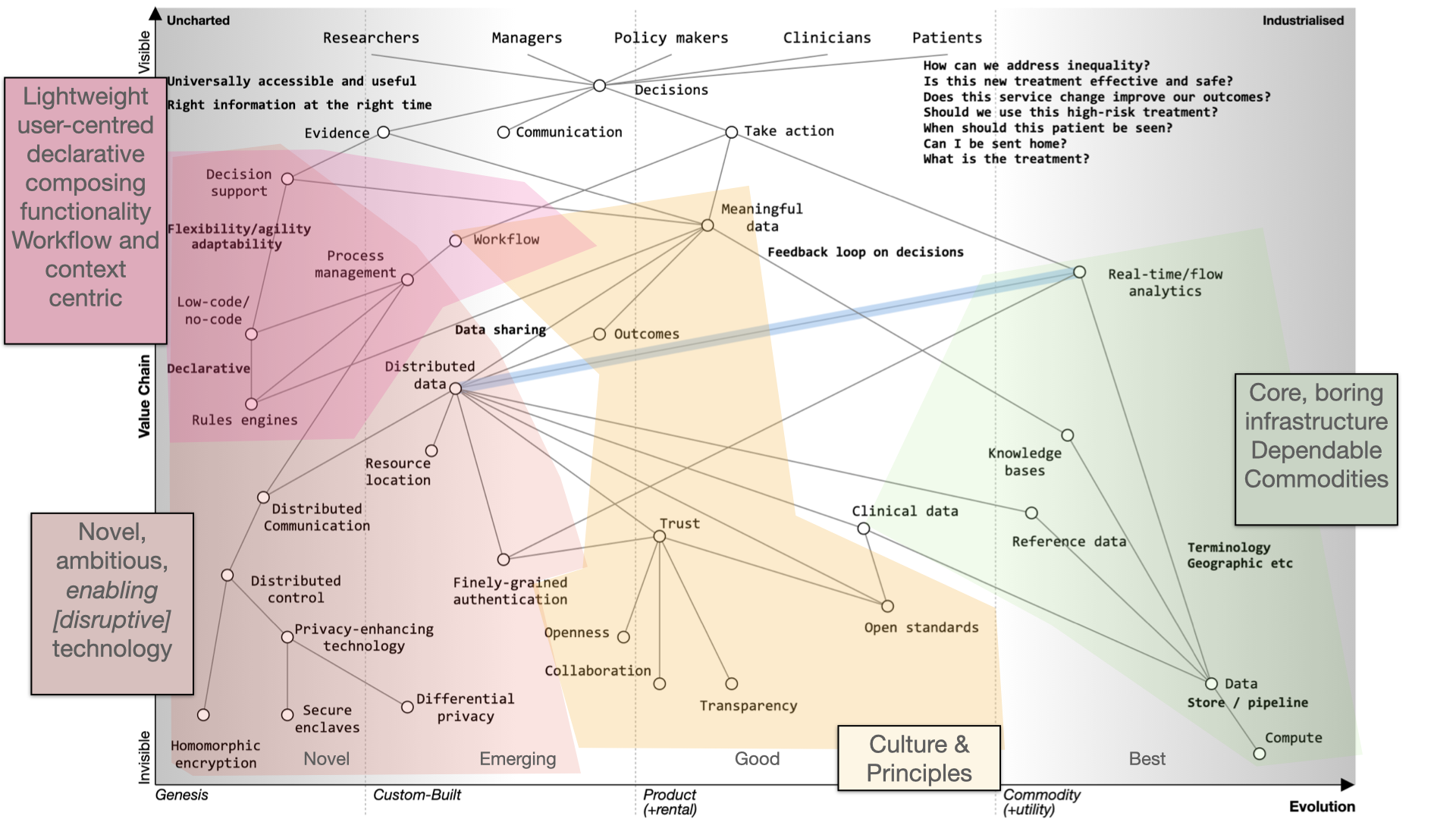


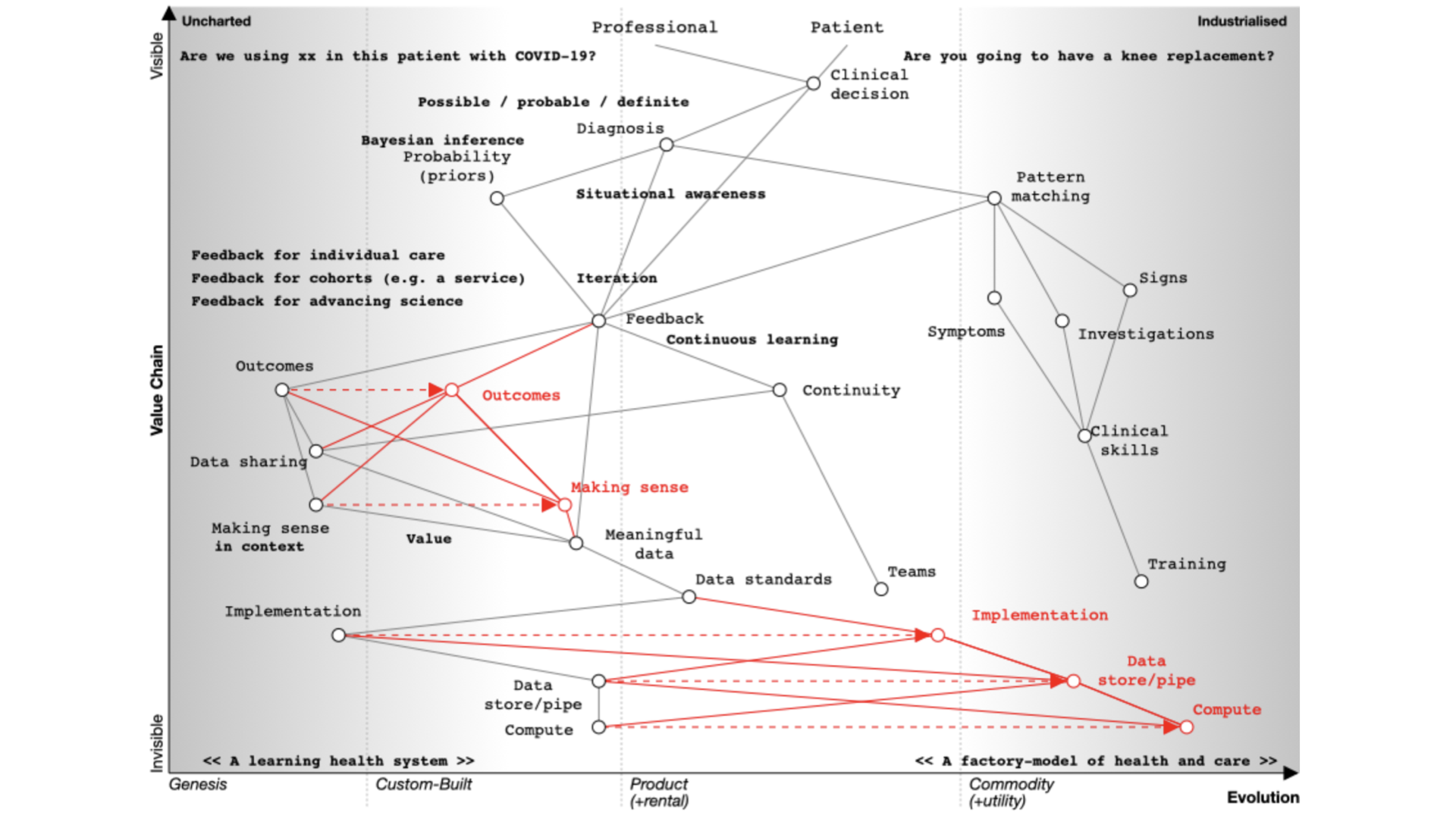
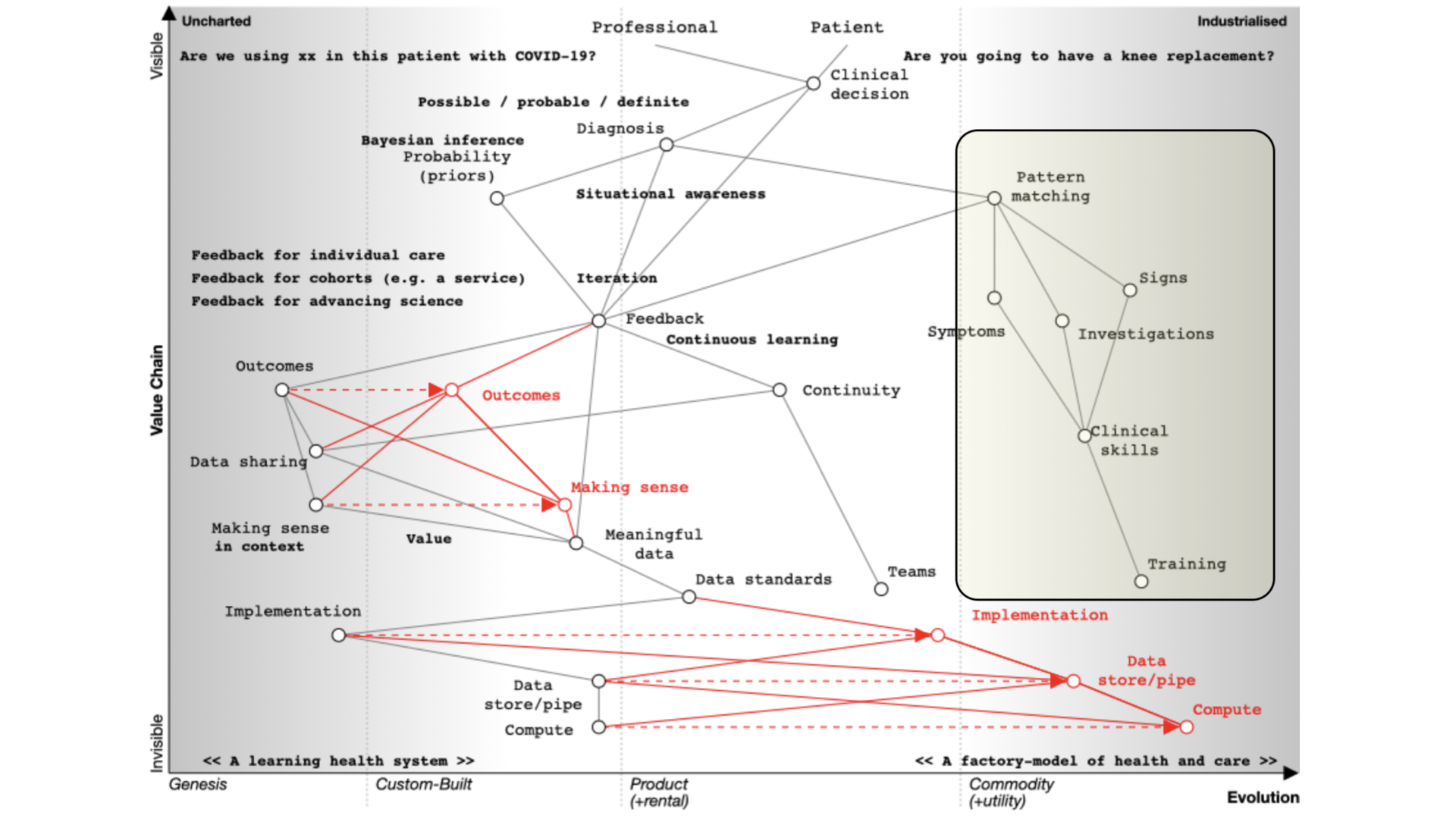 That’s what we teach at medical school and it’s well developed and well evolved. We teach it we expect it to be done propertly and consistently. We look at symptoms, what the patient describes; signs, the things that we can find on examination and we use investigations and all are dependent on training that occurs over many years. It should be no surprise that the patterm-matching pathway is over on the right of our map.
That’s what we teach at medical school and it’s well developed and well evolved. We teach it we expect it to be done propertly and consistently. We look at symptoms, what the patient describes; signs, the things that we can find on examination and we use investigations and all are dependent on training that occurs over many years. It should be no surprise that the patterm-matching pathway is over on the right of our map.